
Get down to business with AI, using off-the-shelf models styles-h2 text-white
<p><span class="medium"><br>June 12, 2023</span></p>
<h2><b><span class="h6">Move beyond AI hype to real-world AI initiatives, using time-tested software development and data management best practices.</span></b></h2>
<p><a rel="noopener noreferrer" target="_blank" href="https://www.cognizant.com/us/en/insights/perspectives/chatgpt-and-the-generative-ai-revolution-wf1532750">Generative AI</a>, which is almost synonymous with ChatGPT these days, continues to <a rel="noopener noreferrer" target="_blank" href="https://techcrunch.com/2023/05/03/chatgpt-everything-you-need-to-know-about-the-ai-powered-chatbot/">make headlines</a> around the world. “What are we doing with ChatGPT?” is a common question. <i>The Wall Street Journal</i> reports venture capitalists are pouring money into AI startups piggybacking on large language models, even when they lack clear business plans. <a rel="noopener noreferrer" target="_blank" href="https://www.fastcompany.com/90839649/google-not-openai-has-the-most-to-gain-from-generative-ai">Big players in the AI space</a> all want to be seen as leading in the generative AI game.</p> <p>What gets lost in all this noise is that proven open-source artificial intelligence/machine learning (AI/ML) models exist right now. These are not mysterious black boxes but are well-documented models. Companies can build successful solutions on these when they follow well-known <a rel="noopener noreferrer" target="_blank" href="https://digitally.cognizant.com/dont-give-up-on-ai-apply-some-mlops-wf1429269">software development and data engineering best practices</a>.</p> <p>That may not sound as exciting as a <a rel="noopener noreferrer" target="_blank" href="https://tcrn.ch/3L49S9E">conversation with Cleopatra</a> via ChatGPT. But the proven rigor of these practices is what will enable companies to drive faster, predictive and proactive decisioning by applying business discipline to their AI initiatives. In addition to setting realistic budgets and timelines, companies will work with transparent models and be able to reuse components to build on and extend their initial AI efforts for even greater utility and returns.</p> <h3><span class="h4" style="font-weight: normal;">A disciplined approach to AI</span></h3> <p>In our experience, only about 10% of corporate AI projects actually get deployed. And while 68% of businesses, globally and across industries, have adopted AI/ML, according to <a rel="noopener noreferrer" target="_blank" href="https://www.cognizant.com/en\_us/insights/documents/ready-for-anything-what-it-means-to-be-a-modern-business-wf1189596.pdf">our recent research</a>, many are struggling to scale their AI initiatives and realize business value from these projects.</p> <p>This trend may also apply to generative AI. In our September 2023 survey of senior business and technology decision makers in the US and UK, 75% said that while their organization understands the potential value of gen AI, they are stuck when it comes to next steps, such as implementation, testing and deployment. Such limited corporate use reflects the sense that AI is an experimental technology to play with vs. applying a structured, disciplined approach.</p> <p>A disciplined approach uses proven data and software engineering frameworks as the foundation for training open-source AI/ML models. Because the frameworks are well established, we know their associated timelines and costs. The business applications of different open-source AI models are clear, such as whether they are better suited for finding and predicting patterns in images or in text. By building a well-structured and trained AI model, businesses can also generate desired results faster. Further, they can apply the model to other situations by training it with different data.</p> <p>One of our clients, an aquaculture major in Norway, wanted a faster and more accurate way of understanding fish development. The company was curious about using computer vision to track growth and detect diseases and malformations. We helped the client train a <a rel="noopener noreferrer" target="_blank" href="https://www.techtarget.com/searchenterpriseai/definition/convolutional-neural-network">convolutional neural network</a> to identify salmon by weight and length. This type of open-source model excels at categorizing images, essentially “encoding” them in its internal connections.</p> <p>With proper design, such as that enabled by our <a rel="noopener noreferrer" target="_blank" href="https://www.cognizant.com/us/en/services/ai/evolutionary-ai">Learning Evolutionary Algorithm Framework</a>, the model will be able to recognize additional patterns. Now, when the client wants to identify additional fish, it does not need to build a new model. Instead, it can use its existing model “off the shelf,” training it with different data sets about other fish species.</p>
#
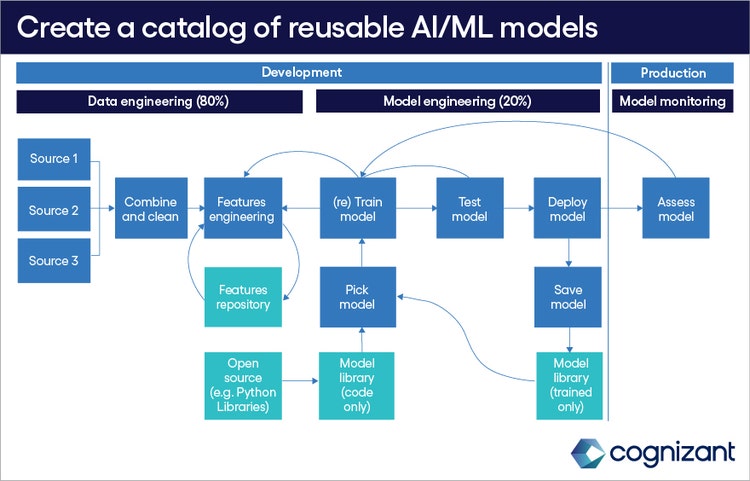
<p><span class="small">Figure 1</span></p> <p><i>Data engineering tasks are the foundation of robust AI/ML solutions built on open resources. Once an organization develops an AI/ML model, the model can be used off the shelf and retrained with new data sets. Companies can create their own repository of off-the-shelf AI/ML models specific to their unique needs.</i></p> <h3><span class="h4" style="font-weight: normal;">The path to off-the-shelf AI/ML models</span></h3> <p>The following steps can help companies create an internal repository of off-the-shelf AI/ML models that are both reusable and extensible:</p> <ul> <li><b>Identify the right model.</b> An AI/ML model consists of code that must be trained with data. There’s a model for every problem type and requirement, from identifying images to “understanding” language in a customer’s email.<br> <br> Companies may choose from a wide range of open-source AI/ML models. These include BERT, <a rel="noopener noreferrer" target="_blank" href="https://www.nvidia.com/en-us/glossary/data-science/xgboost/">XGBoost\ and Neural Networks, as well as those based on Bayesian probability techniques, random forest, logistic and linear regression. Model performance depends on the quality and comprehensiveness of the data on which it is trained.<br> <br> </li> <li><b>Clarify the problem.</b> It’s critical to both define the problem to be solved and define it so AI can solve it. Doing so involves clearly identifying the outcome to be achieved, the metrics by which we will understand whether the solution is acceptable, all the contextual information that must be collected to make predictions accurate, and all the possible actions that can be taken to influence the outcome(s).<br> <br> To illustrate this, let us consider the COVID pandemic. The outcome would be the minimization of contagion and death; the actions would include closing shops and schools, social distancing, mandatory testing and quarantining. The contexts would be all the other variables (things that cannot be controlled) for a specific location, like temperature, rain intensity, social gatherings, events, etc.<br> <br> All the above then defines which data to gather to train the model. The clarity needed here is the same as that for gathering requirements for software engineering. Are you trying to reduce costs? Which ones? Improve sales? Of what and to whom? Increase satisfaction scores? Why and in what areas?<br> <br> </li> <li><b>Make it all about the data.</b> Every data engineering best practice of the last 25 years comes into play as companies identify the data needed for the AI/ML model to solve the specific problem. They need to know: the source of the data, its function, how to assemble and shape the data so the model can use it, and whether derivative data and/or data features are needed. Data must be cleaned, consolidated and normalized. Companies also will need to create an ontology specific to the domain or topic on which the model will operate.<br> <br> Calculating data engineering time and costs for AI models are well-understood processes. Defining the problem and engineering the data requires about 80% of the time spent developing an AI/ML model.<br> <br> For a financial services client, we helped build a model to sort and route high volumes of customer emails to queues for tasks ranging from address changes to increasing credit limits. The outcome was to automate the email classification process by at least 80%. We used a classifier model (BERT), which was trained based on a client-specific nomenclature (i.e., credit, acceptable credit conditions and terms and their changes, address markers, bank details markers). In this case, as part of the data engineering, we created an ontology of terms, working with one of the client’s subject matter experts. We then used the ontology to train BERT.<br> <br> </li> <li><b>Train the model.</b> With data in hand, it’s time to train the model. This is also quantifiable: The amount of data and available processing power determine the required training time. Our general estimate is model training takes about 20% of the model development time.<br> <br> </li> <li><b>Develop a minimum viable product (MVP) and plan for user acceptance testing (UAT) and change management.</b> There are no shortcuts just because it’s an AI/ML model. Companies must test the new processes driven by the trained model with users and refine it as necessary. During MVP time, the user feedback will also be incorporated into the data (i.e., more data, better labeling).<br> <br> </li> <li><b>Go into production.</b> Once tested, the AI/ML model must be integrated with the systems that will use its recommendations and insights.<br> <br> </li> <li><b>Rinse and repeat.</b> The model can be stored in a repository, and, when similar problems arise, it can be used as an out-of-the-box model for training with new/additional data. The same model, using different data, can be used for optimized pricing structures, new product design, logistics delivery network optimization and problem prediction in manufacturing.</li> </ul> <p>Organizations that follow these steps and apply the widely known lessons from software development and data engineering will see more use and value from AI/ML more quickly than those that either dabble with AI technologies or leap into applying large open language models like ChatGPT.<br> <br> Our view is that it is very well possible to create an AI/ML learning service catalog based on the type of prediction to be done by category (i.e., image recognition classification, text recognition and classification, time series predictions, structured data predictions) and their relative complexity (driven by data engineering).<br> <br> The above factors, coupled with the structured approach to industrialize (proof of value, MVP and production) provides a good idea of the effort and budget needed. Of critical importance is also <a rel="noopener noreferrer" target="_blank" href="https://digitally.cognizant.com/dont-give-up-on-ai-apply-some-mlops-wf1429269">a solid MLOPS architecture</a> that allows continuous integration/continuous development (CI/CD) and streaming models in production.</p> <h3><span class="h4" style="font-weight: normal;">Succeeding with off-the-shelf AI/ML models</span></h3> <p>Deployment of AI/ML solutions is, despite the appearance, very similar to other software engineering disciplines. Following a structured approach, within a well-defined MLOPS architecture, owned by a dedicated center of excellence, forms the basis for reusable data products that can be developed with a service catalog mindset.</p> <p>The call to action is clear: Following a structured approach will guarantee scalability and industrialization.</p>

<p>Aurelio D'Inverno is an AVP & AI Transformation Lead in Cognizant’s AI & Analytics practice. He is also a Product Owner in the Cognizant Ocean project. Aurelio holds a Ph.D. in Astrophysics and has 30 years experience in Data and AI space.</p> <p><a href="mailto:Aurelio.D'Inverno@cognizant.com">Aurelio.D'Inverno@cognizant.com</a> </p>