
Make or break: becoming ‘data ready’ for gen AI
data-xy-axis-lg:null; data-xy-axis-md:null; data-xy-axis-sm:60% 0%
<p><br> September 08, 2023</p>
Make or break: becoming ‘data ready’ for gen AI
<p><b>What firms can do today to win, or lose, the generative AI stampede.</b></p>
<p>The release of OpenAI’s ChatGPT 3.5 last November triggered an explosion of excitement around generative Artificial Intelligence (gen AI), in particular the Large Language Models (LLMs), that shows no sign of subsiding. Every day, new gen AI products, companies, and offerings are springing up, while existing businesses scramble to put LLMs to work, harnessing their power to keep pace with, if not overtake, the competition.</p> <p>In all the excitement, though, too many leaders are neglecting one key ingredient of a winning generative AI strategy: data readiness. In our September 2023 survey of senior business and technology decision makers at large businesses in the US and UK, in fact, most executives (74%) said they were unclear on how they will integrate data and manage generative AI across their legacy applications and multi-cloud environments.</p> <p>This article will explain why good data matters so much to gen AI applications, the various factors that make good data “good,” and how firms can get their house in order, data-wise, to reap maximum competitive advantage from these powerful new tools.</p> <h4>Why data matters</h4> <p>‘Normal’ AI has been with us for years. What makes generative AI different, to state the obvious, is that it can <i>generate</i> things. When models like Chat GPT and Dall-E dazzled the world last year by writing flawless original prose, holding fluid conversations, and even producing fantastical works of visual art, many futurists and business leaders predicted this breakthrough would have a profound if simple impact on the future of work: those ‘creative’ tasks today performed by human beings would, soon, be performed more cheaply and efficiently by generative AI.</p> <p>Half a year later, however, a more complex picture has emerged. LLMs, at least so far, are more reliant on human input and monitoring than many initially predicted. In an enterprise context, moreover, there is a growing realization that putting gen AI to work isn’t simply a matter of licensing, or building, an LLM then pressing the ‘Start’ button.</p>
<p><br> In our survey, when asked which data sets were optimal for running AI models effectively, far more execs named proprietary/internal data sets (72%) than trademark-validated data sets (45%) or third-party data sets (43%).</p>
<h4>Two models<br> </h4> <p>So far, two primary approaches have emerged for integrating gen AI with proprietary business data, each with its own set of pros and cons.</p> <h5><b><i>1. </i></b> Custom LLMs</h5> <p>The more ambitious approach starts with a Foundational Model (FM), or a general-purpose LLM, which is then fine-tuned with proprietary data to create an entirely new LLM, and/or AI tools tailored to specific business needs. The process of fine-tuning, particularly with techniques like Reinforcement Learning from Human Feedback (RLHF), requires human input, which can be time and resource intensive. Once complete, the novel tools will also require a further period of monitoring, refinement and maintenance. But with firms with distinct, niche requirements, and the resources for a longer-term investment, fine-tuning FMs with proprietary data is a bold way forward.</p>
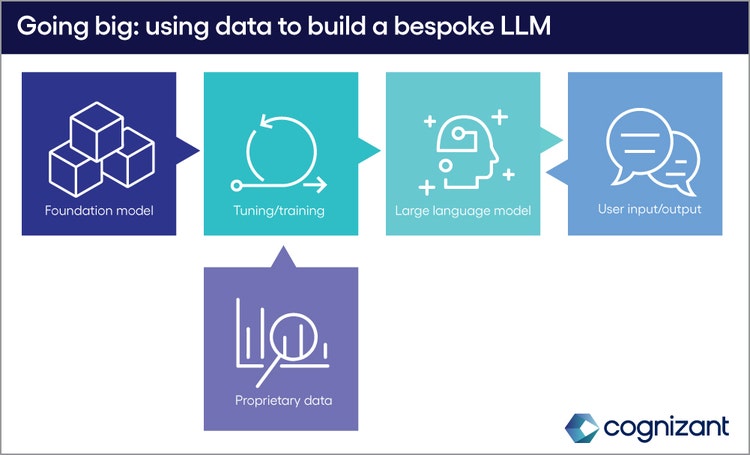
#
<p><span class="small">Figure 1</span></p> <h5><b><i>2.</i></b> “Off-the-shelf” LLMs plus RAG</h5> <p>A quicker, cheaper solution is to use an existing LLM, giving it access to proprietary data through a process known as Retrieval Augmented Generation (RAG). In this approach, the model retains its ‘generic’ core processes, but supplements its output with information retrieved on the fly from proprietary databases.</p>
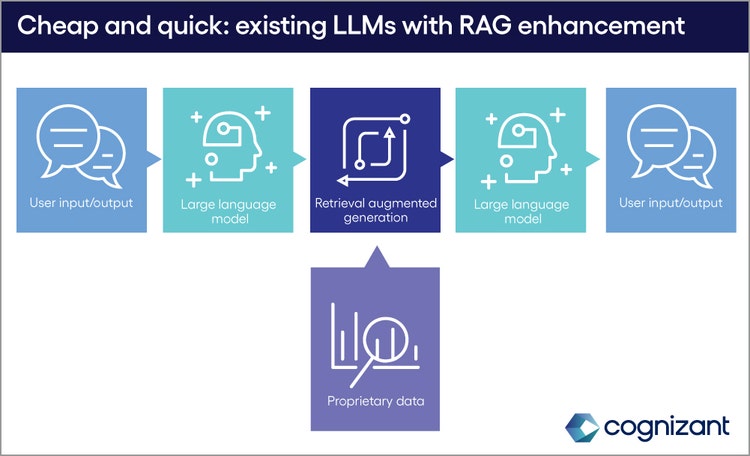
#
<p><span class="small">Figure 2</span></p> <p>As well as speed of deployment and cost efficiency, the RAG approach can also be more flexible than a custom LLM, as its results can reflect real-time changes in data without the entire model having to be trained.</p> <p>Even here, though, the quality of the model’s output, and its overall function, is constrained by the quality and accessibility of the data it has to work with. Whichever approach a business chooses for its generative AI strategy, the odds of success are tightly indexed to how well its <i>existing</i> data architecture performs in the following key areas:<br> </p> <h4>Cataloging and metadata</h4> <p>Data, by itself, is meaningless—even to the sprawling neural network of a modern LLM. The first pillar of data readiness, therefore, is that data be organized in a centralized data repository with comprehensive metadata describing its source, structure, content, and, ideally, meaning. If, as predicted, LLMs will soon be functioning as ‘agents’ for human users, delivering answers and results in response to natural-language queries and instructions, the LLMs not only need access <i>to</i> all relevant data, but to information about the data that gives it context and meaning. Without excellent metadata management, it will be difficult or impossible for LLM agents to be effective.</p> <h4>Reliability</h4> <p>Data must also be accurate—especially if, as in the Custom LLM approach outlined above, it’s to be used for training a generative AI model. Before embarking on their gen AI journeys, companies should determine how much trust their leaders and workers have in their existing analytics, reporting, and or BI (Business Intelligence) dashboards. If the answer is “not much”, the leader would do well to invest in resolving these issues, before pumping resources into training LLMs on substandard data.</p> <h4>Security</h4> <p>The importance of data security is no secret to most modern businesses, but any weak points in existing defenses are liable to be exposed, and quickly, in the coming age of generative AI. Because the behavior of LLMs is not deterministic or precisely predictable—this being the essence of their ‘creativity’—it’s hard to game out in advance how that malicious actors might ‘trick’ an LLM into divulging proprietary data, either about a business or its customers. (This is a particular concern when using a RAG-enhanced off-the-shelf LLM, the approach outlined above. Because the model interacts more frequently with proprietary databases, the risks of a potential breach are multiplied accordingly.) While these threats are to some extent unknowable, though, it’s a safe bet that businesses whose most sensitive data is best protected today will carry this advantage into the era of generative AI.</p> <h4>Speed and flexibility</h4> <p>To maximize gen AI’s potential, firms not only need data pipelines that can provide LLMs with the raw material for processing; they need to be ready to receive and store the torrents of new data that’s produced as a result. The construction of this data architecture needs to happen before the fact, and it needs to be flexible enough to handle a flow of information that may increase linearly or even exponentially in coming years. Expensive data warehouses or even RDBMS systems may start to hinder the amount of data that can be stored and processed cost effectively. It’s not too soon to start exploring modern ‘data lakehouse’ architectures, including scalable cloud object storage systems such as S3 or GCS.</p> <h4>‘Replay’ ability</h4> <p>As the future unfolds, paradoxically, the need to revisit the past will become more pressing and more frequent. The ability to restore or ‘replay’ previous versions of a dataset, is literally indispensable in the training, tuning, and testing of LLMs. Even for firms considering an ‘off-the-shelf’ LLM—pre-trained, pre-tuned and pre-tested—the replay ability of their existing data systems is a useful barometer of overall ‘data readiness,’ heading into the age of generative AI.</p> <p>That goes for all the metrics listed here. Those firms without good data, and just-as-good data architecture, will find themselves at a competitive disadvantage as generative AI transforms the landscape of modern business; they should consider building a solid foundation of data readiness before they invest in their first LLM.</p> <p>Conversely, those companies who already have their data ducks in a row are well positioned not only to reap the rewards of generative AI, but also—probably—of subsequent next big things as yet unimagined.</p> <p><i>To learn more, visit the </i><a href="https://www.cognizant.com/us/en/services/ai/generative-ai" target="_blank" rel="noopener noreferrer"><i>Generative AI</i></a><i> or </i><a href="https://www.cognizant.com/us/en/services/consulting" target="_blank" rel="noopener noreferrer"><i>Consulting</i></a><i> sections of our website or contact us.</i></p> <p><i>This article was written by Jonathan Sims, Consultant in Cognizant’s Consulting practice.</i></p>

<p>We’re here to offer you practical and unique solutions to today’s most pressing technology challenges. Across industries and markets, get inspired today for success tomorrow.</p>