
The path to a more data-driven understanding of the specialty drug patient journey styles-h2
data-xy-axis-lg:null; data-xy-axis-md:null; data-xy-axis-sm:70% 40%
<p><span class="medium"><br>February 10, 2022</span></p>
The path to a more data-driven understanding of the specialty drug patient journey
<p><b>By identifying and then removing obstacles to treatment, pharmaceutical providers can improve patient outcomes, lower costs and maximize revenue.</b></p>
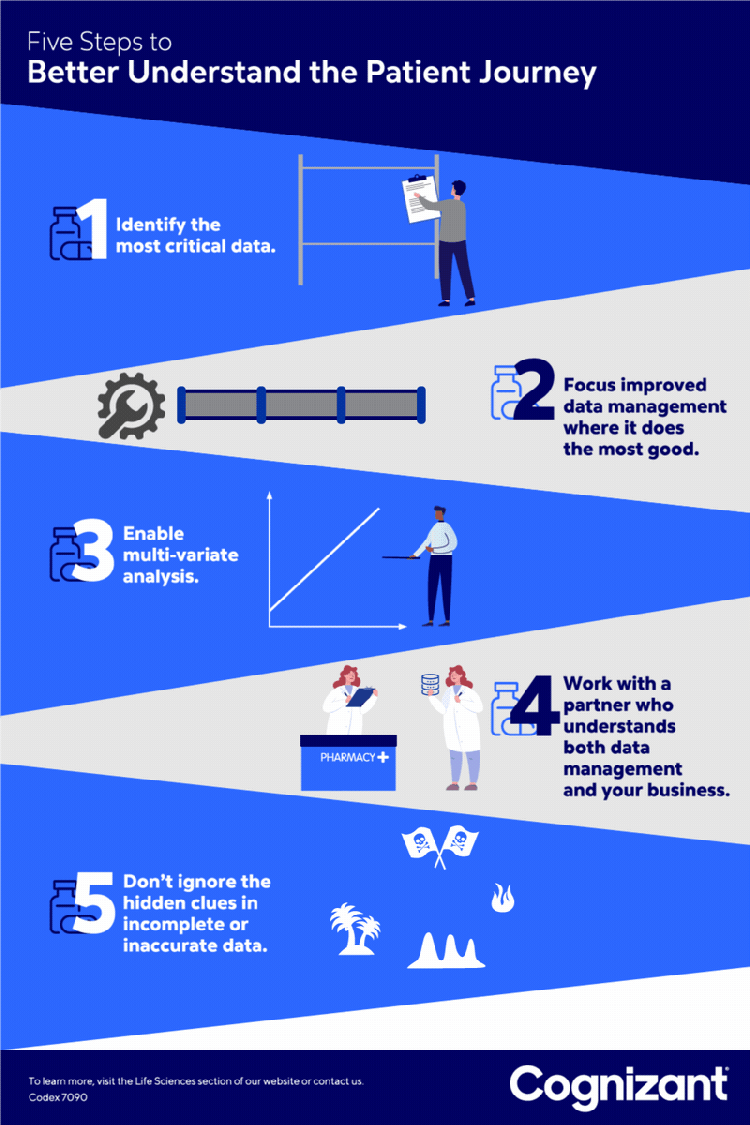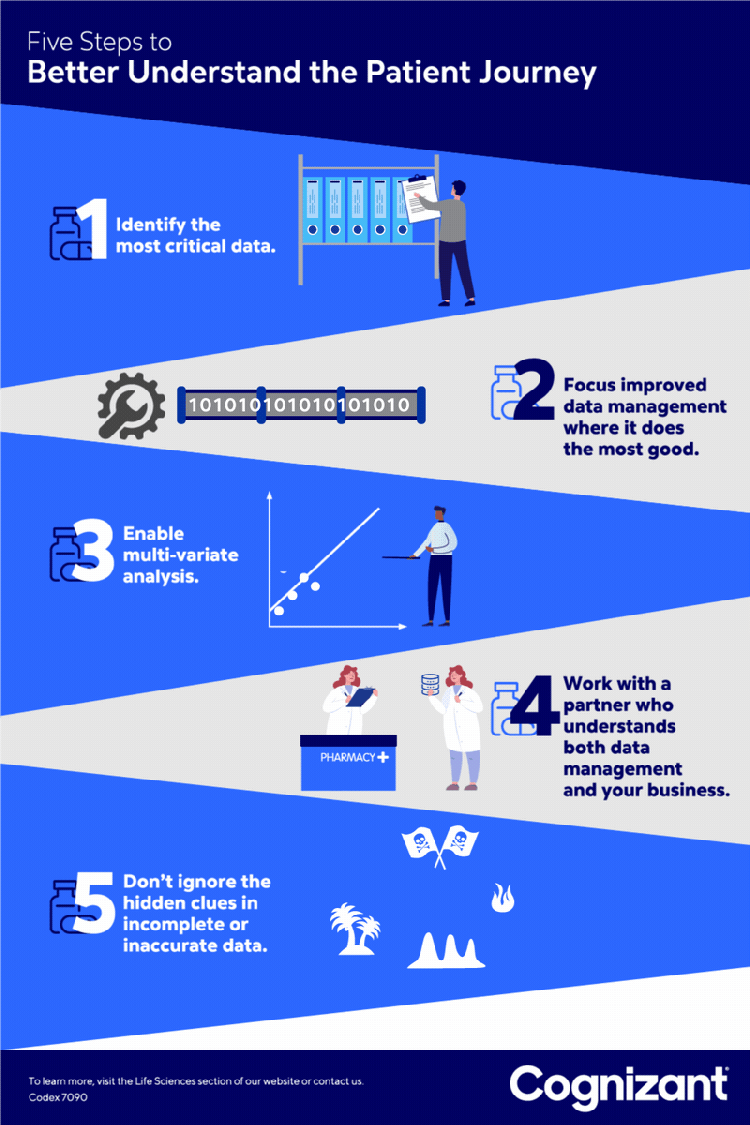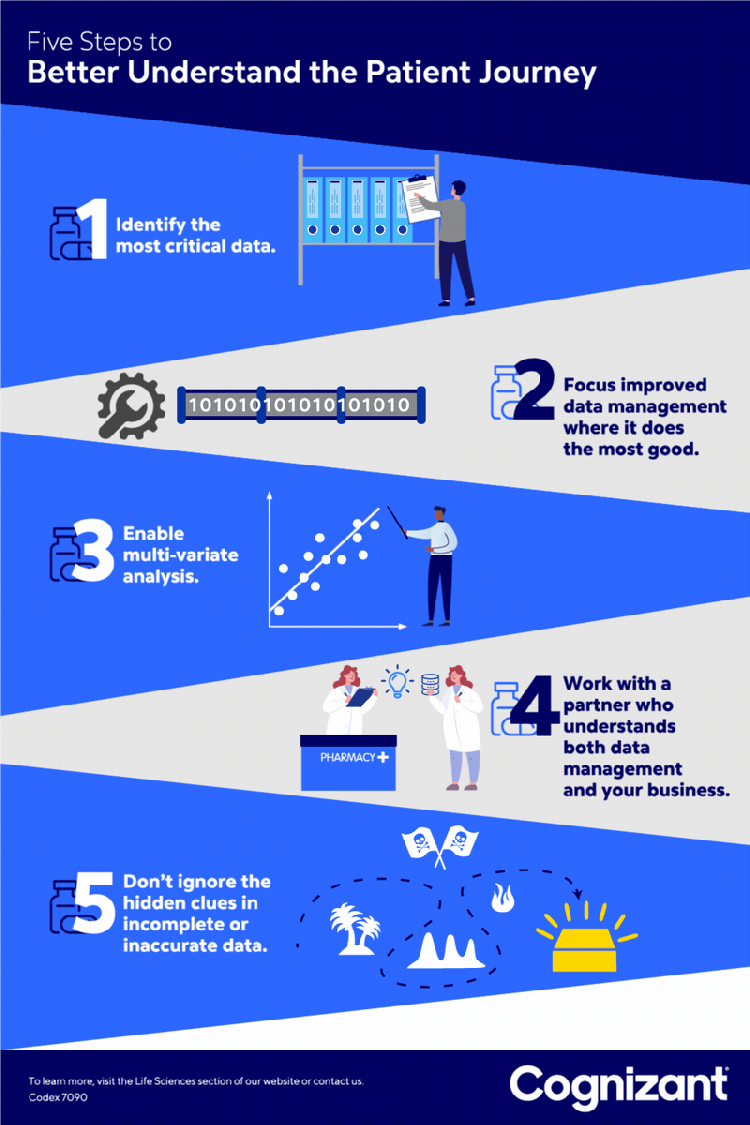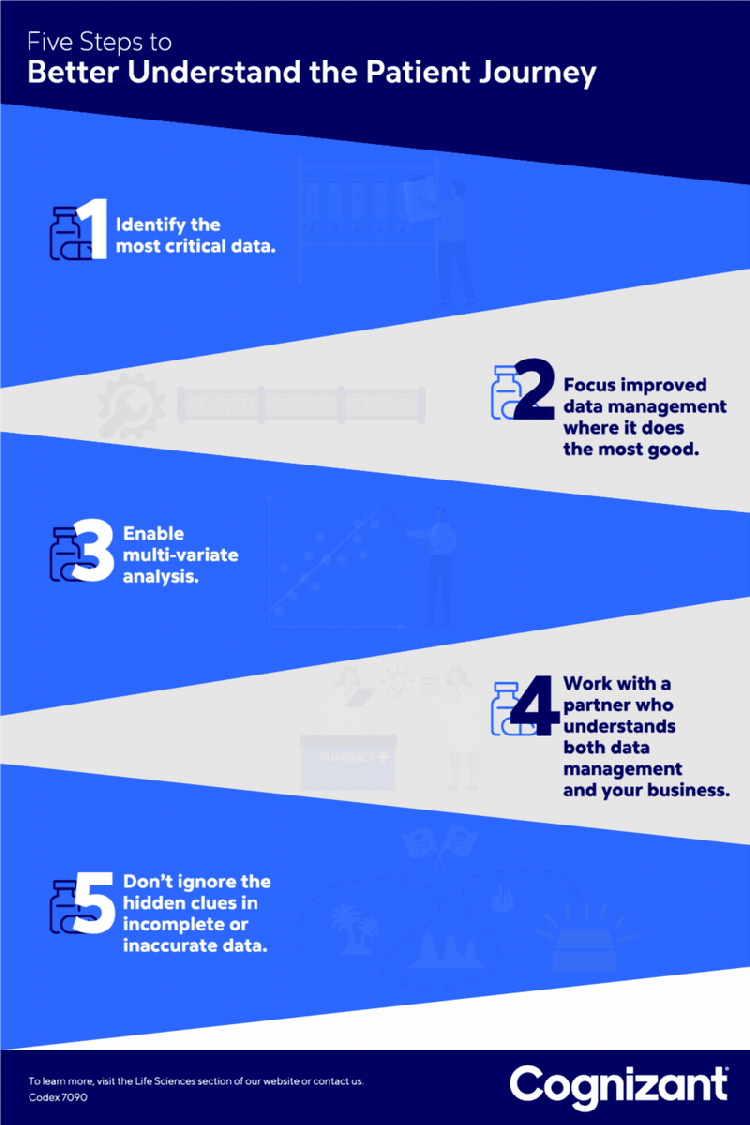
<p>Pharmaceutical companies continue to aggressively roll out new specialty drugs to provide more effective treatment of complex and chronic conditions. The global market for these treatments <a href="https://www.globenewswire.com/news-release/2021/07/08/2259748/0/en/Specialty-Pharmaceuticals-Market-Research-Report-by-Type-by-Product-by-Distribution-Channel-by-Region-Global-Forecast-to-2026-Cumulative-Impact-of-COVID-19.html" target="_blank" rel="noopener noreferrer">was estimated at $34 billion in 2020</a> and is expected to reach $47 billion in 2021.</p> <p>The patient journey for specialty drugs — starting when patients first become aware of a drug and continuing through to their ongoing adherence to its treatment regimen — is a long and complex road. These tend to be expensive treatments that often require special skills to administer. Support services are usually involved, ranging from home health visits to testing to other needed follow-ups. Other common steps on the journey — each fraught with intricacy — include drug prescription, insurer approval for payment, and patient onboarding.</p> <p>Due to this complexity, many eligible patients ultimately fail to receive treatment, leading to poorer patient outcomes, higher drug costs and lost revenue for pharmaceutical providers. In response, pharmaceutical companies (and the “hubs” they often contract with to help guide patients through the treatment process) work to identify obstacles along this journey that come between an eligible patient and successful onboarding or ongoing adherence.</p> <p>However, many struggle to capture enough useful data about the many touch points that determine this. Through our work with leading life sciences clients, we have identified five best practices that can provide faster and higher quality analytic insights to identify and alleviate many common obstacles to treatment.</p> <h5><b><i>1</i>.</b> Identify the patient data most needed.</h5> <p style="margin-left: 40.0px;">Work with stakeholders to focus data preparation on the most pressing patient engagement challenges, rather than the robust yet rigid data design processes historically used by many organizations. This helps ensure organizations capture the most vital data, providing the most useful metrics, key performance indicators and analytic insights.</p> <p style="margin-left: 40.0px;">For example, one pharmaceutical brand might need data on the number of patients who begin but abandon online searches for information about a treatment. For another, the priority might be the number of patients who apply for but fail to gain prior authorization from an insurer for a treatment.</p> <h5><b><i>2</i>.</b> Find data prep sweet spots.</h5> <p style="margin-left: 40.0px;">After pinpointing the patient-related data most needed, identify how to best improve the processes for preparing that data. One example is establishing a unified data format to reduce the cost, complexity and possible challenges associated with consolidating structured and unstructured data from sources such as spreadsheets, text and other file types. Be sure data preparation produces information that meets specific needs, such as showing — in sufficiently granular detail — how long it takes a patient to navigate each step in the treatment journey.</p> <p style="margin-left: 40.0px;">For one pharmaceutical client, we conducted an exploratory analysis of unstructured data to answer key questions about its products and customer expectations. Anonymized case notes from stakeholders were aggregated and synthesized to prepare a taxonomy and ontology for each disease area. We also extracted key words and analyzed both their frequency and potential use as predictive variables.</p> <p style="margin-left: 40.0px;">This allowed us, in consultation with the client, to extract important insights about the patient journey in a compliant manner. One, for example, was that many patients were not taking medication because they were apprehensive about injecting themselves. This allowed the company to consider offering patient support services that would help ease anxiety around home injection.</p> <h5><b><i>3</i>.</b> Make it multi-variate.</h5> <p style="margin-left: 40.0px;">Implement the data quality, integration and preparation required to conduct multi-variate analysis. Such analysis might, for example, identify which insurers in which regions, and for which patients, are most or least likely to authorize payment for a drug. It could also potentially help identify the effects on adherence of variables such as the patient cohort, the required co-pay, or programs rewarding patients for taking medications on time. Such analysis is essential to understanding the many factors, from ease of enrollment to fears about insurance coverage, that can affect patient behavior. This multi-variate analytics-ready data set is also useful to train artificial intelligence models that can be leveraged for various predictive and prescriptive insights.</p> <h5><b><i>4</i>.</b> Don’t discount dirty data.</h5> <p style="margin-left: 40.0px;">Keep an open mind about how even incomplete or inaccurate data can help identify areas that would be useful to analyze. For example, even if the “patient status” fields in a database are inaccurate, other valid information (such as about the prescribing physician) can help identify patterns such as which providers are and are not prescribing a medication.</p> <p style="margin-left: 40.0px;">At the same time, avoid misleading conclusions by understanding not just the source of the data, but the business context in which it is being used to understand the patient’s journey. For example, when a report shows a sudden drop in the number of patients taking a medication, could that simply be due to an incomplete data feed from a business partner or based on a business decision to not renew a payer contract?</p> <h5><b><i>5</i>.</b> Find a one-stop data shop.</h5> <p style="margin-left: 40.0px;">Work with a single data partner that can both provide state-of-the-art data management services and understand the business, rather than one for analytics, one for data management and a third for data science. This helps ensure proper communication of needs and coordination of effort, and reduces management overhead. Such a partner should work to first understand the business challenges (such as helping doctors’ staffs to navigate approval processes) and then doing the detailed work of gathering, cleansing and presenting the data required to meet those challenges.</p>
#
<h4><br> Improved patient outcomes, increased revenue</h4> <p>Using best practices such as these, we have reduced clients’ data preparation costs by up to 20%, while also helping them capture the most vital insights required to understand the patient journey and barriers to treatment. We have used the resulting data to create detailed, brand-specific dashboards describing key performance indicators such as the percent of benefits verification completed, average turnaround time for claims, and the number and type of open cases.</p> <p>For one client, we provided daily alerts to field reimbursement managers for patients who were scheduled to begin therapy the following week but for whom payment had not been authorized. Timely information about the reasons for non-authorization allowed an authorization manager to work with the provider to devise solutions. This reduced the number of such non-adherent patients by 40%, resulting in millions of dollars of additional revenue.</p> <p>We helped another client implement a real-time payer outcome decision mechanism that helps healthcare providers understand whether a drug is likely to be covered. Giving providers more confidence about the likelihood of coverage helped increase this drug’s market share by 15% in four months.</p> <p>By integrating data from multiple sources to analyze delays between the initial and maintenance doses of a neurology drug, we identified causes for the delays and recommended a proactive call schedule and recommending messaging for follow-up calls to patients. This cut five days from the time between the initial and maintenance doses, resulting in significant added revenue over the course of the therapy.</p> <h4>How to get started</h4> <p>To improve patient journey analyses from prescription to treatment, first assess the maturity of processes for gathering, cleansing, processing and analyzing data. Consider determining the data that the organization needs to solve its most pressing business questions, and then assess the quality of that data when it’s received. Discovering data issues at the point of receipt allows organizations to resolve them with far less time and effort than later in the analytic process.</p> <p>With data management gaps identified, consider the strategies, processes and technological capabilities needed to address them. For example, what is the right mix of hub data vs. third-party claims to answer specific questions? How should the process of data stewardship using robotic process automation be established? Could the organization leverage a data management cloud to help bring together the most effective and efficient ways of achieving the analytics objectives?</p> <p>These are increasingly important questions. With the ongoing discovery and development of new specialty drugs and therapies and continual changes to reimbursement coverage, patients will find it increasingly difficult to understand which available treatments can help them, how those treatments should be taken, and how much they’ll cost out-of-pocket. Understanding the patient experience through a continuous analysis of data about those experiences will help patients get access to the treatments they need, and pharmaceutical providers achieve the market share they desire.</p> <p><i>To learn more, visit the <a href="/content/cognizant-dot-com/us/en/industries/life-sciences-technology-solutions.html" target="_blank" rel="noopener noreferrer">Life Sciences</a> section of our website or <a href="/content/cognizant-dot-com/us/en/about-cognizant/contact-us.html" target="_blank" rel="noopener noreferrer">contact us</a>.</i></p> <p><i>This article was written by Vinamra Singhania, Life Sciences Commercial Data, Analytics and Sales Ops Leader at Cognizant.</i></p>

<p>We’re here to offer you practical and unique solutions to today’s most pressing technology challenges. Across industries and markets, get inspired today for success tomorrow.</p>