
Without AI, your data strategy is already obsolete
<p><br> <span class="small">July 21, 2025</span></p>
<p><b>As enterprises prepare to embed AI in their processes and operations, AI will also be essential for transforming the data strategy.</b></p>
<p>To lead in an AI-first world, enterprises must rethink how they manage, govern and extract value from data. Traditional data strategies—designed for static reporting and compliance checkpoints—can no longer keep pace with the demands of intelligent, real-time operations. What organizations need is a data strategy built to fuel real-time decisions, intelligent automation, continuous value creation and trust at scale.</p> <p>Yet many organizations remain stuck. Legacy platforms, fragmented data ownership and unclear business alignment make it challenging to determine where to start.</p> <p>The key is to plan for not only how AI can reinvent processes and operations but also how AI can transform the data strategy itself. An AI-driven data strategy shifts data from a passive asset to an active driver of competitive advantage. For chief data officers, CIOs and heads of data, the challenge is no longer whether to embed AI into the data strategy; it’s how to do it effectively and measurably.</p>

#
<p><span class="small">Figure 1</span></p> <p>In this blog, we offer a pragmatic approach for developing an AI-driven data strategy. Through practical examples and clear steps, we’ll show how to rewire your data strategy, not just for efficiency but also for enterprise-wide impact.</p> <h4>How to make AI real: 6 ways to embed AI Into the data strategy</h4> <p>Through our work with clients, we’ve developed six actionable steps that leaders can take to start embedding AI in their data programs. These are designed to tackle foundational challenges, like trust, quality and scale, through an AI-first lens.</p> <h5><span style="font-weight: normal;"><span class="text-bold-italic">1.</span> Start with one high-value use case, and build backwards</span></h5> <p>Rather than revamping your entire data strategy at once, take a more targeted approach. Begin by identifying a business-critical problem, like reducing customer churn or speeding up claims processing, and piloting an AI solution focused on that. You can then work backwards to align data pipelines, governance and quality. <br> <br> For example, if you choose claims processing, you’ll likely need to: </p> <ul> <li>Ingest structured and unstructured data from policy systems, adjuster notes and third-party data providers.</li> <li>Implement data lineage and access controls for sensitive information (e.g., personal health data) under regulatory frameworks.</li> <li>Establish quality checks to identify inconsistencies in claim types, missing policyholder details or incomplete payout histories. Doing so ensures clean data is fed into models that assess fraud risk or predict processing times.</li> </ul> <p>This targeted, reverse-engineered approach helps ground your AI investment in a real business outcome while gradually building the data foundation required for broader transformation. </p> <h5><span style="font-weight: normal;"><span class="text-bold-italic">2.</span> Use AI to automate and improve metadata management</span></h5> <p>Businesses can use AI-enabled tools to automatically discover, categorize and tag data across systems, building a dynamic, real-time data catalog. This means your teams can instantly see what data exists, where it came from, how it's used and whether it's reliable, without relying on manual spreadsheets or tribal knowledge.</p> <p>For example, we worked with a global financial services firm to develop an AI-powered data catalog to classify client onboarding data, transaction records and regulatory compliance logs across its cloud and legacy systems. The system auto-tags datasets with regulatory classifications (e.g., GDPR-sensitive, Know Your Customer data) and assigns domain ownership to relevant risk and compliance officers. This enables analysts and compliance teams to quickly find and validate datasets for anti-money laundering (AML) monitoring, reducing regulatory reporting time by 40%.</p> <p>With AI-managed metadata in place, business users can confidently launch analytics initiatives, ensure compliance with internal data policies and reduce dependency on central data teams. Without it, organizations face slower time-to-insight, duplicated efforts and a greater risk of using outdated or non-compliant data for critical decisions.</p> <h5><span style="font-weight: normal;"><span class="text-bold-italic">3.</span> Turn governance into an active, AI-supported process</span></h5> <p>Enterprises should move from static policy enforcement to a more intelligent, real-time governance approach by integrating AI agents with machine learning models that continuously monitor and manage data usage across the enterprise. These agent-driven systems can analyze access logs, detect anomalies in data behavior and automatically flag or block activities that violate governance policies.</p> <p>For example, AI agents can detect when an analyst attempts to export personally identifiable information (PII) data from a customer table without proper role-based access, then trigger alerts or initiate automated policy workflows for approval or investigation.</p> <p>This enables governance teams to transition from reactive audits to proactive controls, enhancing compliance accuracy while minimizing operational overhead. Without this approach, governance remains slow, error-prone and reliant on periodic manual reviews that may miss critical violations until it's too late.</p> <h5><span style="font-weight: normal;"><span class="text-bold-italic">4.</span> Productize your data with AI-enabled quality scoring</span></h5> <p>Businesses should also treat critical, reusable datasets as data “products,” complete with documentation, ownership, access controls and AI-generated trust scores. These scores reflect factors such as data lineage, completeness, update frequency and past quality issues, enabling teams to quickly assess whether a dataset is ready for use in analytics or AI.</p> <p>For example, a marketing team might access a “customer behavior data product” with a trust score of 92%. That score reflects the data’s freshness (updated daily), usage (frequently queried for churn prediction) and validated schema. A campaign analyst can self-serve this data, without requesting IT help, knowing it’s fit for targeting high-risk segments.</p> <p>While not every dataset needs to be productized, applying this approach to high-impact AI-ready data makes it easier to scale use cases, reduce redundancy and build trust in data-driven decisions. Without it, teams often duplicate datasets, second-guess quality or spend days validating data before they can act, delaying insights and adding unnecessary friction.</p> <h5><span style="font-weight: normal;"><span class="text-bold-italic">5.</span> Build a cross-functional delivery pod around data + AI</span></h5> <p>Multidisciplinary pods should be established that own the delivery of AI-powered data products end-to-end. These pods should include data engineers, MLOps specialists, domain SMEs and product owners. This accelerates deployment and ensures continuous iteration based on business feedback.</p> <h5><span style="font-weight: normal;"><span class="text-bold-italic">6.</span> Evolve your data platform for an AI-native architecture</span></h5> <p>The data platform should be modernized to support the full lifecycle of AI, from ingesting data and training models to pushing them into production. A key component is implementing feature stores, which serve as “pantries” for storing commonly used data inputs, such as a customer's average monthly spend or last login date. This allows these data inputs (or “features”) to be reused consistently and efficiently across different models.</p> <p>For example, if both a fraud detection and credit scoring model use a customer's transaction history, a feature store ensures the logic and data used are always accurate and up to date, saving time and avoiding errors.</p> <p>Platform modernization also includes adding real-time data pipelines, tools that track and monitor the accuracy of AI models over time and modular services (so you can plug in new components without overhauling the whole system). <br> <br> This type of platform allows organizations to scale AI with speed, transparency and reliability. Without it, AI initiatives become brittle, siloed and difficult to govern, often stuck in pilot mode or failing in production due to mismatched infrastructure.</p> <h4>A framework for AI-driven data strategy transformation </h4> <p>Once you understand these key building blocks, the next step is to execute them in a structured manner. Don’t try to “transform everything.” Start small, deliver impact, then scale. This step-by-step framework provides data leaders with a repeatable playbook for integrating AI into their strategy.</p>
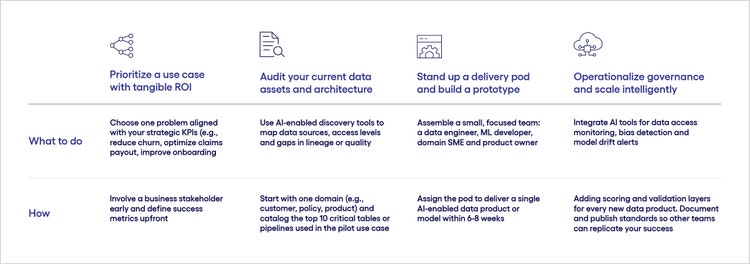
#
<p><span class="small">Figure 2</span></p> <p>Think of this as your first loop: start with one win, make it visible, and scale what works. This builds credibility and lowers resistance to broader platform and operating model shifts.</p> <h4>Let AI drive, not just support, your data strategy</h4> <p>AI is no longer a “nice to have” layer on top of data infrastructure; it’s the engine that powers a modern data strategy. Leaders who take a proactive, use-case-driven approach and invest in intelligent governance, automation and platform capabilities will unlock measurable business value faster.</p> <p>The question is no longer “Should AI be part of our data strategy?” but rather “How fast can we make AI central to it?”</p> <p> </p>

<p>Naseer is a data and technology leader with 14 years of experience in data strategy, governance, and enterprise architecture. He helps organizations modernize their data platforms, enabling data-driven and AI-augmented decision-making. Passionate about transforming data into business value, Naseer is focused on advancing agentic AI to power the next generation of intelligent enterprise solutions.</p>
