El lanzamiento, en noviembre del año pasado, de ChatGPT 3.5 de OpenAI ha generado toda una expectación alrededor de la inteligencia artificial generativa y, en concreto, sobre los grandes modelos de lenguaje natural (LLMs). Cada día surgen nuevas compañías, productos y ofertas de IA generativa mientras que las organizaciones ponen los LLMs a trabajar, aprovechando su poder para seguir el ritmo, sino superar, a la competencia.
En medio de esta expectación, todavía hay muchos líderes que desatienden uno de los componentes clave de una estrategia de IA generativa ganadora: la preparación del dato. En una encuesta que realizamos en septiembre de 2023 a responsables sénior de la toma de decisiones de negocio y de tecnología en EE.UU. y Reino Unido, la mayoría de los participantes (74%) dijo que no tenían claro cómo integrar los datos y la IA generativa en las aplicaciones legacy y en los entornos multi-cloud.
Este artículo explica por qué los buenos datos son importantes para las aplicaciones de IA generativa, los diferentes factores que hacen “buenos” los datos y cómo las organizaciones pueden poner en orden sus datos para conseguir la máxima ventaja competitiva de estas herramientas.
Por qué lo datos importan
La IA ‘normal’ lleva con nosotros años. Lo que hace a la IA generativa diferente es su capacidad para generar cosas. Cuando modelos, como Chat GPT y Dall-E, deslumbraron al mundo al escribir prosa original, mantener conversaciones fluidas e, incluso, producir obras extraordinarias de arte visual, muchos líderes predijeron que este logro tendría un profundo impacto en el futuro del trabajo: aquellas tareas creativas que hoy realizan los seres humanos, pronto las realizaría de forma más eficiente y asequible la IA generativa.
No obstante, medio año después nos enfrentamos a un entorno más complejo. Los LLMs, al menos, son más dependientes de la aportación y la monitorización de los humanos de lo que muchos predijeron en un principio. En el entorno empresarial, existe una mayor comprensión de que poner a la IA generativa a trabajar no es solo una cuestión de obtener la licencia o desarrollar un LLM y luego presionar el botón de arranque.
En la encuesta, cuando preguntamos sobre qué conjuntos de datos eran óptimos para correr modelos de IA de forma efectiva, la mayoría de los participantes nombró los datos propietarios/internos (72%) frente a los conjuntos de datos validados por la marca (45%) o datos de terceros (43%).
Dos modelos
Hasta ahora, han surgido dos enfoques principales para integrar la IA generativa con los datos propietarios, con sus propios pros and contras.
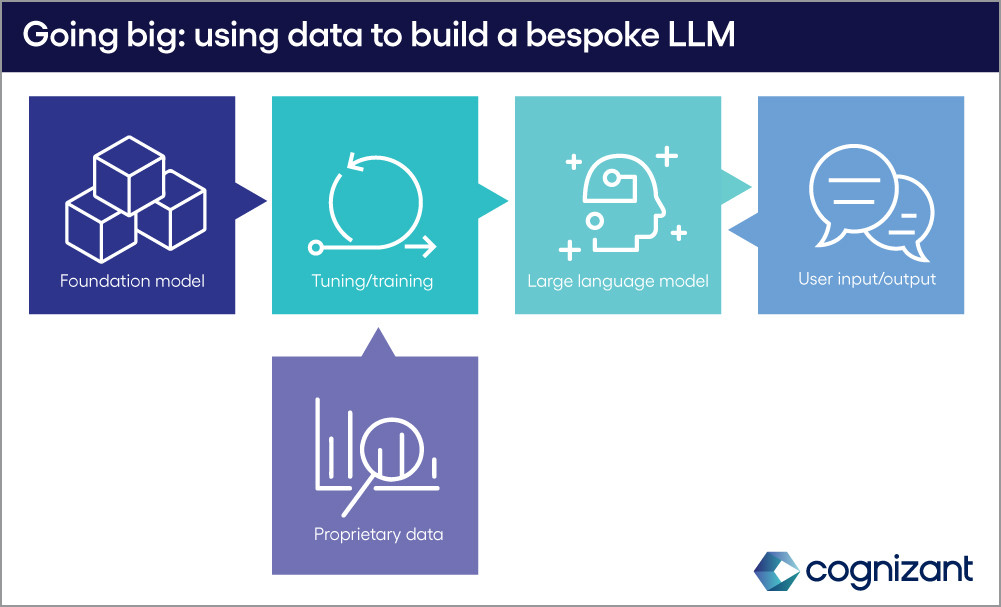
1. LLMs personalizados
El enfoque más ambicioso empieza con un modelo fundacional (Foundational Model, sus siglas en inglés FM), o un LLM de propósito general, que se ajusta con datos propietarios para crear un LLM completamente nuevo y/o herramientas de IA diseñadas para necesidades específicas del negocio. El proceso de ajuste, en concreto las técnicas Reinforcement Learning from Human Feedback (RLHF), exige aportación humana, que puede ser intensiva en tiempo y recursos. Una vez que se completa, las nuevas herramientas también requerirán un mayor período de monitorización, reajuste y mantenimiento. Pero con las organizaciones con requisitos de nicho distintos y los recursos para invertir a largo plazo, ajustar los FMs con datos propietarios es una valiente salida adelante