Many enterprises pursue a multi-cloud strategy favoring platform neutrality. To what extent can this principle be upheld in the new AI era, especially with the rise of Generative AI, without overly restricting innovation?
The benefits of the cloud are compelling. Even in Europe, there is no longer any doubt that cloud transformation is crucial for business agility and competitiveness. Hence, almost all enterprises are moving to the cloud, namely Amazon Web Services (AWS), Microsoft Azure or Google Cloud Platform (GCP). Overall, we are on a path towards all IT applications of all Western world enterprises running on the three hyperscale cloud platforms. To reduce the risk of vendor or platform lock-in, enterprises typically pursue a multi-cloud strategy, which must now also take into account the specific challenges of AI/GenAI.
Real barriers to cloud neutrality
As outlined in the related article “Multi-cloud – Don’t get trapped by the illusion of cloud platform neutrality” the fallacy is often drawn that you can move at will between the cloud platforms if you only use platform-independent services. In this regard, enterprises tend to overreact by banning all platform-specific, serverless services, which often represent the cutting edge of innovation. This limits the benefits of cloud transformation and AI/GenAI adoption while overlooking the real challenges of multi-cloud portability.
The services of AWS, Azure and GCP differ, but in most cases the other platforms offer similar, albeit not identical, services. Thus, cloud-native applications and its source code can usually be migrated to another cloud provider, even if some platform-specific services are used. For example, it takes some effort to port AWS Lambda to Azure Functions or Google Cloud Functions, but this is rather the least of the problems of a cloud platform switch.
The greater challenges and effort arise from the fundamental differences between the three platforms in the areas of cloud governance, cloud operations, security and networking. Moreover, big data represents a major barrier to multi-cloud, as all three players charge high egress costs. Moving a data lake is costly. With AI/GenAI driven by data, strategic enterprise data management is becoming even more imperative.
Impact of AI on multi-cloud strategies
In contrast to classical applications, which are explicitly programmed in functional or object-oriented programming languages, AI models are not coded but trained with large amounts of data. In a sense, enterprise data is baked into the underlying neural network, or more precisely, into the weights and parameters of virtual neurons. As Generative AI based on multimodal Large Language Models (LLMs) moves past the Proof-of-Concept (PoC) phase and increasingly into large-scale adoption, the associated risks of vendor lock-in must be assessed and mitigated.
Will AI, and particularly Generative AI with LLMs, greatly increase the gravitational pull of the three hyperscale cloud platforms? Could even monopoly or oligopoly structures emerge?
First, the good news is that there is no area more dynamic than AI/GenAI, with lots of start-ups and a steady stream of innovative solutions. So, there seems to be plenty of choice and no serious lock-in risk. However, in the end, all AI/GenAI-powered applications run on the three hyperscalers. Without the limitless scalability of the hyperscale cloud platforms, there would be no GenAI revolution. Against this background, is it possible to migrate AI/GenAI models from one cloud platform to another? In principle, yes, but it depends on the details. The entire technology stack and the model development and deployment process, including all frameworks and tools, must be looked at. So, let's do that briefly.
AI model development
At first, a distinction must be made between training a model from scratch and using an existing, pre-trained model. The trend is towards pre-trained models, as this approach is less complex and there are more and more models for all kinds of use cases. Only tech companies will develop new LLMs themselves, but there are customer-specific predictive analytics use cases for which it still makes sense to train an AI model from scratch. As with in-house developments, the risk of vendor lock-in then lies not in the model itself, but in the frameworks, tools and technologies applied.
In the other case, model development means that the most suitable pre-trained model is selected and adapted to the specific purpose. With more than 1 million models to be found on e.g. Hugging Face alone for all kinds of use cases, you are spoiled for choice. Thus, model evaluation is a challenge. But anyhow, there is no such thing as the best model – definitely not for all and not even for one use case. In face of a highly innovative and dynamic market, always keep the flexibility to switch to a better or more cost-effective model at a later stage.
Principally, open-source vs. proprietary models must be differentiated. With open-source models, the model details are publicly disclosed, and deployment is usually feasible on any platform. It must be checked whether commercial use is permitted. Examples for open-source LLMs are BLOOM, Llama (Meta), Bert (Google), Falcon or Dolly (Databricks).
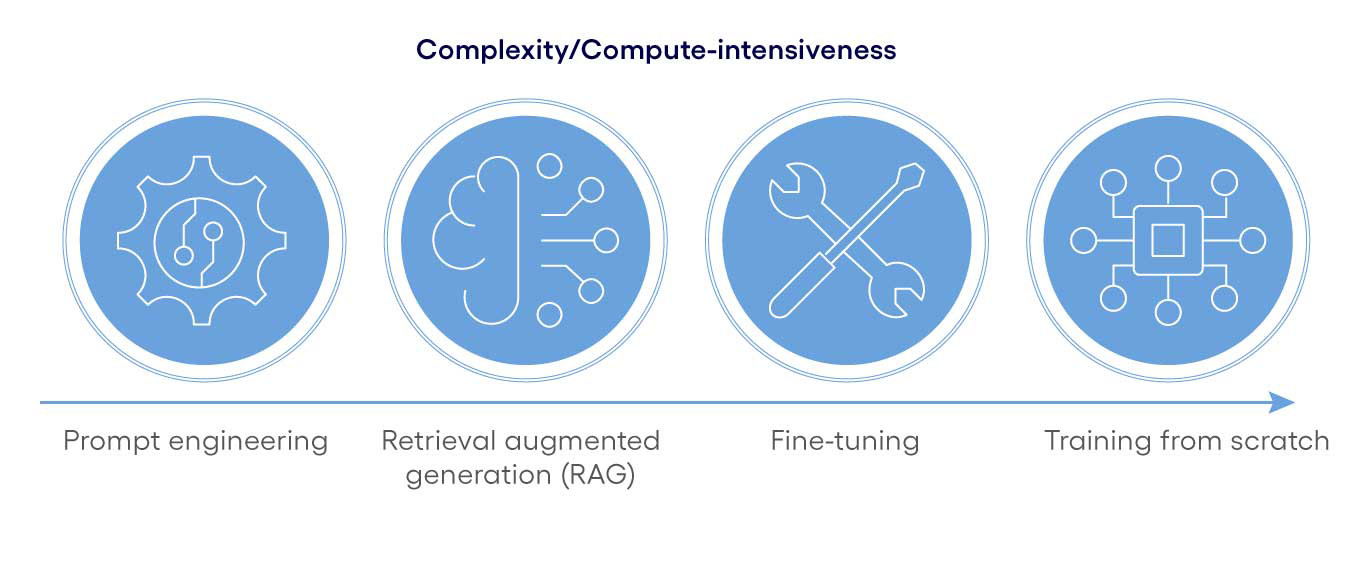
With proprietary models, not only the pricing but also the customization options must be considered. Some models are LLMaaS (LLM as a service), which do not allow for custom deployment or fine-tuning. Well-known proprietary LLMs are OpenAI GPT, which runs exclusively on Azure, and Gemini, which runs only on GCP. Those two are currently rated as most cutting-edge LLMs. However, for reasons of price, performance, sustainability (energy consumption) and vendor lock-in mitigation, it is best practice to select not necessarily the first ranked leader, but a sufficiently good model, that can often be better adapted to the specific requirements of the use case. For this purpose, the following three approaches are pursued, also in combination:
- Prompt engineering is about crafting and iteratively refining effective prompts, which provide clarity, contextual information and illustrate the expected outcome by examples. Consistency is ensured by creating prompt templates.
- Retrieval-Augmented Generation (RAG) enhances AI models by integrating an authoritative internal knowledge base. Typically, relevant documents are collected, converted, tokenized and incorporated. The RAG-optimized model takes this knowledge and context into account for each given answer.
- Fine-tuning involves training a model on a new, task-specific dataset. This allows the model to learn new patterns and relationships from the new data while preserving the knowledge acquired during pre-training. This process leads to a new model variant that is more accurate and specialized for the respective use-case.