Dans cet article, nous explorons la notion de contexte et comment celui-ci peut éclairer différemment les données et les modèles, en délivrant des informations uniques et parfaitement ciblées. En rendant opérationnelle cette notion à travers le context engineering, l’entreprise peut ainsi espérer exploiter de bout en bout son patrimoine data et fluidifier les opérations et la prise de décision.
Qu’est-ce qu’un « contexte de données » ?
Pour comprendre ce qu’est le context engineering, il faut d’abord s’interroger sur ce que signifie la notion de contexte dans une perspective Data.
Prenons un joggeur après 40 minutes de course. Sur son application de sport habituelle s’affichent ses données de performance, de rythme cardiaque, de calories, etc. Mais sur l’application d’électrocardiogramme (ECG) de sa montre connectée, il découvre une alerte : son rythme cardiaque serait trop élevé, l’appli l’invite à consulter un médecin sans tarder.
Le constat est clair : ces applications ne communiquent pas entre elles. Et l’appli ECG n’est pas sensibilisée au contexte particulier du joggeur qui vient d’effectuer un effort physique important. Cet exemple peut faire sourire mais, appliqué à des situations à plus fort enjeu, il n’est pas sans conséquence.
Prenons maintenant le secteur des services financiers. Que penser des situations suivantes ?
- Un modèle de conformité qui identifie des transactions inhabituelles mais qui ne distingue pas s’il s’agit d’un simple rééquilibrage de portefeuille ou d’un délit d’initié.
- Un modèle de risques qui dégrade la note d’un client à la suite d’un événement de liquidités sans tenir compte de l’historique de fiabilité de ce client ni de ses garanties.
- Un refus de crédit opéré uniquement sur la base de la situation étudiée et non sur la base des données d’historique (probablement stockées dans des systèmes legacy).
Ces exemples le montrent : lorsque la data n’est pas contextualisée, le processus de décision se trouve rallongé pour recouper les informations, et la confiance dans l’automatisation peut en sortir altérée. L’enjeu de ces prochaines années réside donc dans la capacité de l’entreprise à capturer ce contexte (ou plutôt ces différents contextes) dans tous les recoins de l’entreprise, et à le rendre opérationnel pour le traitement des données et les applicatifs IA.
Le context engineering
C’est cet objectif que compte remplir le context engineering : proposer un cadre de travail réunissant les données et métadonnées mais aussi des informations sur les intentions, les éléments de langage et les relations entre les équipes pour faire comprendre à l’intelligence artificielle le « sous-jacent » des questions auxquelles elle est censée répondre.
Contrairement au prompt engineering qui visait à concevoir la meilleure question possible pour l’IA, le context engineering se concentre sur l’alimentation du modèle avec toutes les informations nécessaires : les prompts des utilisateurs, les instructions systèmes (comme la définition des personas et des fonctions de chacun), l’historique des interactions, les préférences des utilisateurs, les règles internes à l’entreprise, le patrimoine scientifique et culturel des équipes et les données transactionnelles.
Tous ces contenus doivent pouvoir être mobilisés directement par le LLM dans sa fenêtre de contexte et être présentés de façon à garantir une réponse pertinente du modèle – une approche qui permet également de dépasser les limites habituelles des LLM (manque de mémoire, dépendance aux données tierces, taille limitée de la fenêtre de contexte) à travers la continuité de l’information et l’orchestration des interactions.
Contexte statique vs contexte dynamique
Deux typologies de données contextuelles peuvent alors être identifiées :
- Les données issues d’un contexte dit « statique » : il s’agit ici d’éléments relativement immuables comme les types de fonctions au sein de l’entreprise, les règles internes, les processus de travail et les limitations. Par exemple, un agent IA de détection des fraudes pourrait être programmé pour signaler des jeux de transactions particulièrement complexes et volumineux à travers des informations comme la devise, les montants, le pays d’origine, le type de compte bancaire, etc. mais aussi en appliquant des règles de conformité spécifiques à l’entreprise. L’échelle de réponses à appliquer serait alors indexée sur les procédures internes.
- Les données issues d’un contexte dit « dynamique » : il s’agit des facteurs variables soumis à une rapide évolutivité, comme les demandes clients ou les données opérationnelles en temps réel. Par exemple, si un client appelle un assureur pour mettre à jour l’adresse de son parking, un agent IA peut considérer cette information comme une opportunité commerciale et créer une entrée CRM indiquant ainsi au service commercial de reprendre le dossier. Autre exemple : dans l’industrie, le context engineering permet aux agents IA de mobiliser les données des capteurs, les actualités météo et les commentaires des opérateurs pour ajuster les plannings de production et d’expédition et éviter ainsi les à-coups logistiques.
Mieux cibler l’IA, valoriser l’ADN de l’entreprise
Le context engineering permet donc de combler le fossé qui existe entre les promesses de l’intelligence artificielle et ses utilisations encore trop timides et non ciblées par l’entreprise : désormais l’IA est pleinement connectée à la réalité opérationnelle des équipes et peut être exécutée dans les processus.
Mais ce n’est pas le seul apport du context engineering. Car, en agrégeant les données patrimoniales de l’entreprise (la mémoire de ce qui est, de ce qui aurait dû être, de ce qui fonctionne, de ce qui n’a pas marché, des solutions trouvées, des échecs surmontés, etc…), le context engineering donne une matérialité à la sagesse collective de l’organisation et infuse cette connaissance unique et inédite dans les processus. Ce n’est plus seulement un savoir-faire transmis aléatoirement mais un ADN mis à disposition de toutes les équipes dans une perspective d’apprentissage continu et de développement. Dans cette perspective, le context engineering est la discipline qui fait basculer l'IA d'un outil générique à un atout stratégique pour amplifier les éléments différenciants de l’entreprise.
Construire des pipelines de contexte
Reste cependant à répondre à l’enjeu d’implémentation car la conception de solutions agentiques appuyées sur une ingénierie de contexte robuste ne se fait pas en un claquement de doigt : une telle transformation nécessite une gouvernance continue, des itérations et un engagement à conserver en permanence la pertinence des données de contexte. Si la dernière décennie s’était attelée à la constitution de pipelines de données robustes et précis, les années qui s’ouvrent seront probablement orientées vers le développement et la gouvernance de pipelines de contexte : les « fabriques à contexte ». Il s’agit en effet de construire ce tissu intermédiaire entre la donnée et les process, en intégrant les systèmes transactionnels, les métadonnées et les raisonnements métiers.
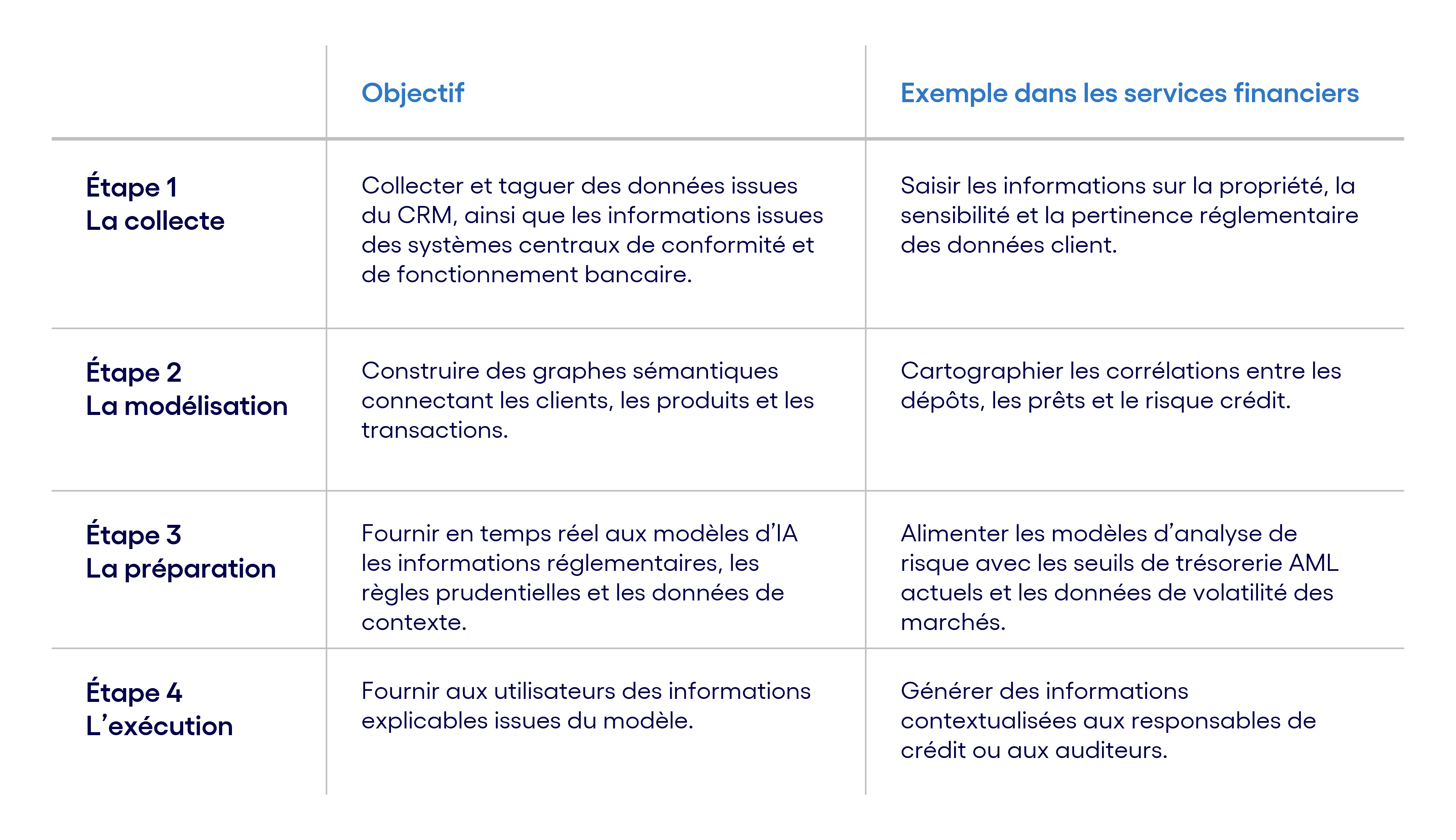
Nous décrivons ici quelques étapes permettant de construire cette fabrique à contexte dans la perspective de services financiers :