De la théorie au concret : six étapes pour intégrer l’IA dans la stratégie de données
Dès lors, le défi pour les CDO, CIO et responsables data n’est plus de s’interroger sur l’intérêt d’intégrer de l’IA dans la stratégie de données mais bien de trouver les moyens de le faire efficacement et de manière mesurable.
À travers notre expérience client, nous avons pu identifier six étapes concrètes pour opérer cette transition, d’une stratégie traditionnelle à une stratégie alimentée par l’IA. Par des exemples pratiques, cette feuille de route vous donne un aperçu de comment votre entreprise pourrait progressivement adresser les problématiques de confiance, de qualité et de passage à l’échelle via l’IA.
Suivez le guide !
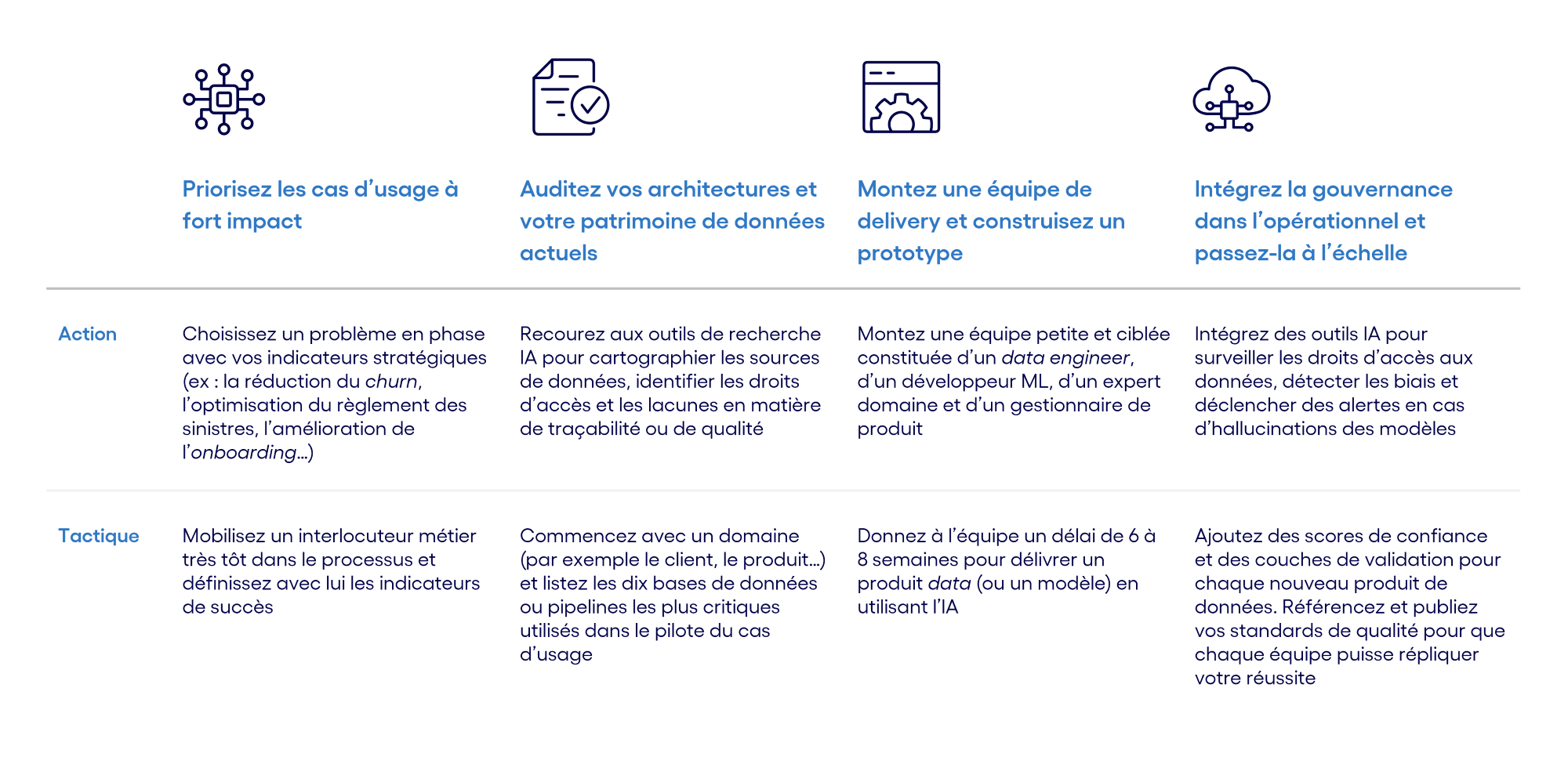
Étape 1 : Partez d’un cas d’usage à fort impact
Plutôt que d’élaborer un plan complexe portant sur l’intégralité de votre stratégie de données, nous vous recommandons d’adopter une approche plus ciblée. Commencez par identifier une problématique métier transversale qui impacte fortement l’activité – par exemple, la réduction du churn ou l’accélération du traitement des demandes clients – et lancez la conception d’une solution IA capable d’adresser ce besoin dans sa globalité. Ce travail mettra en lumière les challenges amont de gouvernance, de qualité et de pipelines de données qui pourront ainsi être traitées empiriquement, avec un impact sur l’ensemble de l’entreprise.
Prenons un exemple avec le traitement des demandes d’indemnisation chez un assureur. Au cours du processus de création et de développement IA, il est fort probable que celui-ci se retrouve confronté aux enjeux suivants :
- L’intégration de données variées (structurées et non structurées) provenant de diverses sources : polices d’assurances, comptes-rendus d’expertises, données issues de partenaires…
- La mise en place de processus de traçabilité des données et d’accès restreint aux informations sensibles (comme les données de santé des clients), dans le strict respect des cadres réglementaires du secteur de l’assurance et de la gestion des données.
- L’établissement de contrôles réguliers pour vérifier la qualité des données d’entrée dans les modèles de détection des fraudes ou d’anticipation des délais de traitement : il s’agit notamment de filtrer en amont les incohérences dans les déclarations de sinistres, les informations manquantes sur les assurés ou les historiques de versements incomplets…
En identifiant et adressant ces problématiques progressivement par reverse engineering, l’entreprise peut ainsi s’assurer que son investissement dans l’IA est opérationnel et associé à un résultat business tangible (le ROI du cas d’usage) tout en posant les bases d’une transformation plus globale à travers une architecture de données adaptée.
Étape 2 : Exploitez l’IA dans la création et la gestion des métadonnées
Quelles sont les données de mon patrimoine ? D’où proviennent-elles ? Comment sont-elles utilisées ? Sont-elles fiables ?... L’impératif d’une réponse en temps réel sur ces questions n’est plus à démontrer. Vos équipes ont besoin d’accéder à ces informations de manière dynamique et instantanée, sous forme de catalogue, sans avoir à mobiliser des calculs ou des connaissances particulières.
Pour les aider, il est donc indispensable de recourir à des outils IA capables d’identifier, catégoriser et indexer les données de façon automatique.
À titre d’illustration, nous avons travaillé avec une entreprise internationale de services financiers qui souhaitait ordonner plusieurs types de données, réparties sur les systèmes cloud et legacy de l’entreprise. Il pouvait s’agir de données d’onboarding clients, d’enregistrements de transactions, ou encore de journaux de conformité…
Nous avons alors conçu un catalogue de données alimenté par l’IA qui assigne automatiquement des classifications réglementaires aux différents jeux de données (par exemple : « soumis au RGPD », « données KYC ») et attribue ainsi la propriété du domaine aux responsables des risques et de la conformité concernés. Cette procédure automatisée permet aux analystes financiers et aux équipes de conformité d’identifier et de valider rapidement les jeux de données dans le cadre des procédures anti-blanchiment (AML), avec un temps de reporting réglementaire abaissé de 40 %.
De façon générale, la mise en place de ces métadonnées gérées par l’IA permet aux équipes métiers de lancer des requêtes analytiques de manière plus systématique et fiable. Ils peuvent ainsi se passer de recourir aux équipes data centrales et assurer une totale conformité aux politiques internes de l’entreprise. Cette efficience opérationnelle est forcément synonyme de réduction des temps d’analyse des données, de rationalisation des efforts entre équipes et d’abaissement des risques d’obsolescence ou de non-conformité des données.
Étape 3 : Automatisez la gouvernance grâce à des agents de contrôle
Aujourd’hui, vos mesures de contrôle sur l’utilisation de vos données est essentiellement réactive et ponctuelle ? Nous vous recommandons d’envisager l’intégration d’agents IA et de modèles de machine learning pour une approche bien plus dynamique et intelligente de votre gouvernance : grâce à ces outils, les usages data peuvent être monitorés et gérés en permanence à l’échelle de toute votre entreprise. Les systèmes d’agents peuvent en effet analyser l’historique des accès, détecter des anomalies dans les comportements des données et signaler ou bloquer les activités qui semblent violer les politiques internes de gouvernance.
Par exemple, les agents IA peuvent désormais détecter si un analyste tente d’exporter des données susceptibles d’identifier une personne (les PII = personally identifiable information) depuis un fichier client sans en avoir l’autorisation ni l’accès. Les agents peuvent alors déclencher une alerte ou initier un process automatique de contrôle qui conduira à une autorisation ou à une enquête sur cet événement.
Cette évolution dans les outils conduit à un vrai changement de paradigme pour les équipes de gouvernance : elles passent ainsi d’audits réactifs à des contrôles proactifs, qui augmentent la précision du suivi de conformité tout en minimisant l’effort opérationnel. Sans cette approche, la gouvernance est condamnée à rester trop lente, trop approximative dans ses conclusions, avec une dépendance forte à des systèmes de surveillance périodique qui ne constituent malheureusement pas une barrière étanche aux menaces.
Étape 4 : Donnez un score de qualité à vos données
En tant qu’actifs de l’entreprise, vos jeux de données critiques et réutilisables sont particulièrement scrutés : vos équipes ont besoin d’évaluer rapidement leur qualité et leur capacité d’utilisation immédiate pour une requête analytique.
Il est donc cohérent de les envisager comme des « produits », c’est-à-dire des articles caractérisés par une documentation, un acte de propriété, des droits d’accès et des scores de confiance attribués par l’IA. Ce score s’appuierait en partie sur des facteurs comme la traçabilité de la donnée, son niveau de complétude, la fréquence de ses mises à jour et les signalements passés autour des enjeux de qualité.
Ainsi, une équipe marketing pourrait tout à fait accéder à un produit nommé « données du comportement consommateur » noté à 92 % sur l’échelle de la confiance – ce score reflétant la fraîcheur des données (c’est-à-dire une mise à jour quotidienne), la réalité de leur usage (elles sont régulièrement requêtées pour des prédictions de churn) et leur historique de validation. L’analyste d’une campagne marketing pourrait ainsi puiser dans ces données en toute autonomie sans avoir à demander l’aide des équipes IT et il pourrait sereinement les exploiter, y compris sur des problématiques critiques pour l’entreprise.
Même si cette approche « produit » ne peut être appliquée à tous les jeux de données de l’entreprise, il est important de la mettre en place pour des données à fort impact et à forte maturité IA car elle permet de passer des cas d’usage à l’échelle, de réduire les doublons et de construire la confiance. Sans elle, les équipes sont plus souvent enclines à dupliquer les jeux de données, à interroger leur niveau de qualité ou à passer des jours à valider les données avant de pouvoir les mobiliser… du temps perdu et des contraintes inutiles que l’IA peut facilement lever.
Étape 5 : Créez des équipes polyvalentes autour des données IA
La création de ces « produits data » alimentés par l’IA devra avoir un corollaire organisationnel : l’établissement de petites équipes multidisciplinaires prenant en charge ces produits de bout en bout jusqu’à leur livraison. Dans ces unités, collaboreraient ainsi des ingénieurs data, des spécialistes MLOps, des experts domaines et des responsables de produits. Cette polyvalence permettra d’accélérer le déploiement et d’assurer une amélioration continue grâce au feedback des métiers.
Étape 6 : Faites évoluer votre plateforme de données pour une architecture adaptée à l’IA
Pour supporter l’intégralité du cycle de vie de l’IA, depuis l’ingestion des données et l’entraînement des modèles jusqu’à l’entrée de ceux-ci en production, il est nécessaire que votre plateforme de données soit modernisée.
Un composant essentiel que nous suggérons est la conception d’un « magasin » stockant les données les plus fréquemment utilisées (par exemple : les dépenses moyennes d'un client par mois ou sa date de dernière connexion) afin de pouvoir les mobiliser régulièrement et de façon cohérente sur différents modèles. On peut alors parler de feature stores (« magasin de données ») pour désigner ces architectures qui permettent la réutilisation à l’échelle.
Par exemple, si l’historique des transactions d’un client est utilisé à la fois par un modèle de détection des fraudes et par un modèle de notation des crédits, un feature store permet de garantir la fiabilité des données et leur pertinence pour le modèle IA, évitant ainsi beaucoup d’erreurs et de perte de temps.
Ce n’est pas le seul aspect que nous recommandons dans cette modernisation : pour une intégration dynamique de l’IA, il vous faudra concevoir des pipelines de données spécialisés sur le temps réel, mais aussi des outils qui surveillent en permanence la pertinence des modèles IA, ou encore des services modulaires (afin que vous puissiez brancher de nouveaux composants sans avoir à remanier l’intégralité du système).
Cet effort de modernisation est indispensable pour passer rapidement l’IA à l’échelle en toute transparence et fiabilité. Sans cette dernière étape dans le parcours, les initiatives IA que vous aurez menées risquent de s’enferrer dans des phases pilotes qui échoueront en production par inadéquation de l’infrastructure (silotée, difficile à gouverner).
Synthèse sur la méthodologie
Une fois que vous avez compris ces étapes-clés de transformation, il ne vous reste plus qu’à les exécuter de la façon la plus structurée possible. N’essayez pas de « renverser la table » . Commencez petit, générez de l’impact, et ensuite passez à l’échelle. Cette méthodologie progressive fournira à vos managers data un manuel de référence qu’ils pourront répliquer à l’envi pour intégrer l’IA dans leur stratégie.