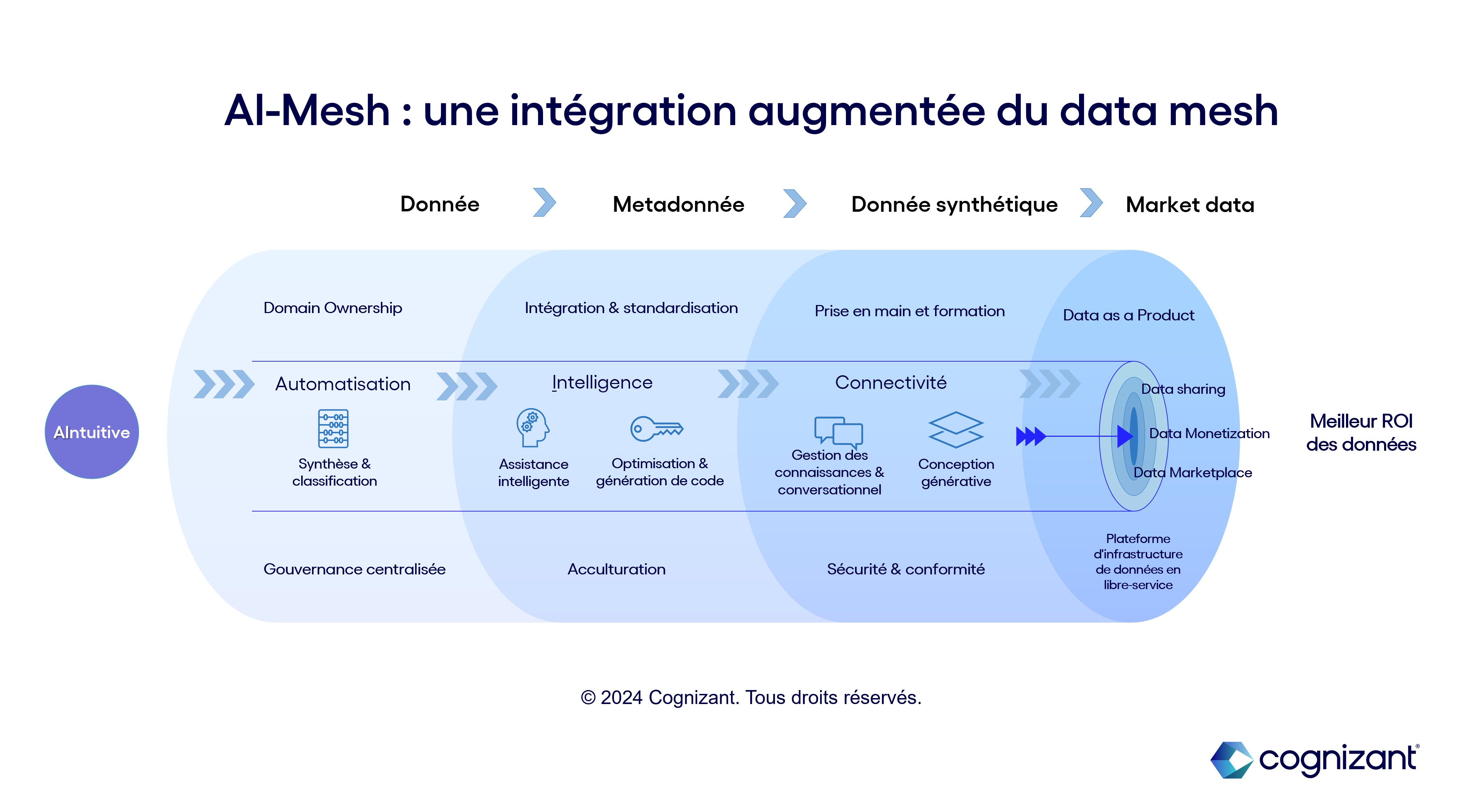
D’une gestion centralisée des données à une vision orientée usage, qui confie la responsabilité de la donnée aux équipes métiers, le data mesh transforme la prise de décision dans les entreprises : la donnée y est traitée comme un produit (Data as a Product ou DaaP) et chacun peut accéder aux catalogues en libre-service, réduisant ainsi considérablement les temps d’attente et les goulets d’étranglement du système centralisé.
Cependant, ce nouveau paradigme d’organisation des données ne doit pas masquer des défis importants à relever, en matière de gouvernance comme de sécurité.
Pour surmonter ces difficultés, l’IA générative peut être un précieux allié et accélérer ainsi l’adoption des data mesh dans les infrastructures. À la clé : une exploitation plus efficace et ciblée des données par les métiers et, à terme, une transformation de la donnée en actif échangeable, voire commercialisable.
4 attributs fondamentaux pour définir le data mesh
Appelé également maillage de données, le data mesh vise à décentraliser l'architecture de données pour une meilleure centralisation de l’utilisation afin de permettre aux différentes fonctions de l’entreprise de gérer et s’approprier des données relatives à leur propre domaine d’activité (marketing, opérations, ventes, finance, back office etc.). Cette autonomie dans la gestion et l’usage des données doit permettre d’accélérer la prise de décision localement.
Afin de mieux comprendre comment fonctionne le data mesh, il importe de se pencher sur les 4 attributs fondamentaux qui permettent de le définir :
- Domain Ownership (responsabilité sur le domaine) : Ce principe signifie que les équipes métiers sont pleinement responsables des données qui se rapportent à leur activité ; elles sont chargées de s’en occuper sur toute la durée de leur cycle de vie, et doivent veiller à enrichir la donnée et ses métadonnées au regard du contexte spécifique du domaine.
- Data as a Product (approche produit) : Cette notion signifie que les données sont considérées comme un produit à part entière, dont les équipes de domaine ont la charge ; celles-ci deviennent alors des « fournisseurs de données » et les équipes amenées à utiliser ces données se muent en « consommateurs ». La notion de produit s’incarne alors dans le format de transmission de la donnée : celle-ci est fournie avec une documentation, des garanties de qualité et un guide d’exploitation… Une nomenclature qu’on pourrait comparer à celle d’un article sur catalogue.
- Plateforme d'infrastructure de données en libre-service : Pour permettre aux équipes consommatrices d’accéder aux données et de concevoir rapidement des produits issus de ces données, il est nécessaire que l’entreprise développe une plateforme unifiée capable de proposer des outils et des systèmes agnostiques capables d’être mobilisés sur différents domaines sans modification. Ceux-ci faciliteront alors la construction, l’exécution et le maintien de produits de données interopérables au sein de toute l’entreprise.
- Gouvernance centralisée : Pour éviter que cette approche décentralisée ne génère des silos et des doublons, il est nécessaire que l’entreprise mette en place un comité de gouvernance qui assure l'interopérabilité de tous les produits de données. La normalisation, le respect des règles organisationnelles et les réglementations sectorielles seront au cœur de ses missions.
Surmonter les difficultés du data mesh : 5 facteurs clés de succès
Si les bénéfices d’une approche data mesh ne sont plus à démontrer (responsabilité partagée, meilleur accès à la donnée, agilité et passage à l’échelle ainsi que l’autonomie des équipes), la mise en place opérationnelle et le déploiement d’une telle stratégie comportent de nombreuses difficultés. L’organisation de l’entreprise, l’héritage data et la maturité technologique sont autant de critères qui doivent être évalués avant d’embarquer dans l’aventure data mesh.
Parmi les défis envisagés lors de l’implémentation, on retrouve :
- Le défi d’acculturation, tous acteurs du changement : Au-delà de la maturité dans la culture data en général, l’adoption de la philosophie du data mesh est une évolution radicale qui nécessite un renouvellement d'état d'esprit de toute l’organisation. Les métiers sont responsabilisés tandis que les fonctions informatiques passent de data lakes centralisés à une approche décentralisée. Ce bouleversement en matière de responsabilités, fonctions et process peut susciter des résistances qu’il importe d’adresser dès le début du projet.
- La cohérence globale des données et l’intégration des domaines : Le passage à une organisation décentralisée peut poser des problèmes en matière de cohérence, d’interopérabilité et de collaboration autour des données. Il est donc indispensable d’assurer une intégration fluide entre les différents domaines : pour cela, un travail de coordination et de communication doit être mené, tout comme la mise en place d’une stratégie d’intégration de données, au travers d’outils de standardisation notamment.
- La prise en main et la formation des équipes « fournisseuses » et « consommatrices » : La formation est essentielle pour développer les compétences de l’ensemble des équipes en charge des données. Il s’agit d’acquérir des compétences mais aussi de se familiariser avec ce qu’il est possible de faire. S’agissant des équipes consommatrices, une prise en main intuitive de la plateforme de self-service est indispensable pour permettre à chacun de manipuler en toute autonomie les produits data. Ce prérequis implique un travail technique important pour concevoir, maintenir et passer à l’échelle les pipelines de gestion de données.
- Les enjeux de sécurité et de conformité : Le caractère décentralisé d’une architecture data mesh peut conduire à de nouvelles problématiques en matière de sécurité et de confidentialité : dans cette optique, il importe a contrario de centraliser les protocoles de sécurité en établissant un contrôle des accès plus précis, des mécanismes d’authentification et mesures de protection des données qui devront s’adapter aux règles détaillées du domaine d’application.
- L’interopérabilité des données : L’écosystème opérationnel est composé de plusieurs briques, technologies, formats, et la donnée passe du système d’origine, unique et cohérent, à un ensemble complexe d’outils qui ont vocation à la transformer. Dans cette optique, l’enjeu de traçabilité est important mais aussi celui de l’interopérabilité pour assurer une fluidité dans le transfert de la donnée. L’utilisation finale (la « consommation ») constitue un défi majeur d’interopérabilité, les données d’usage étant vouées à être partagées au sein (mais aussi à l’extérieur) de l’entreprise.
Comment l’IA générative peut-elle permettre d’accélérer l’implémentation du data mesh ?
Face à ces défis, les investissements en temps, équipes, ressources et planification peuvent être décourageants. D’où un besoin d’automatisation et d’assistance qui peut être partiellement comblé du côté de l’IA générative.
En effet, pour atteindre les objectifs de disponibilité, d’accessibilité et de qualité du data mesh, et accélérer le déploiement de celui-ci à l’échelle de l’entreprise, l’IA générative pourrait agir à plusieurs niveaux :
- Aide à l’harmonisation des référentiels et à l’établissement d’une gouvernance centralisée. En identifiant plus rapidement la structure des données et en classifiant celles-ci par domaine/usage ou par origine et format, l’IA générative est capable d’automatiser plus rapidement la gestion des données à l’échelle de l’entreprise. Par-dessus tout, les référentiels créés peuvent permettre d’indexer ces données sur plusieurs domaines sans générer des doublons.
- Soutien à l’enrichissement de la donnée : L’IA générative peut guider les équipes métiers dans leur travail d’enrichissement de la donnée, lorsqu’elles produisent de la connaissance autour de celle-ci via les métadonnées (contexte de donnée, connexion entre données, etc.). Cette assistance peut intervenir également lors de la production de la documentation qui entoure la donnée devenue Data-as-a-Product (guide, contrat, garantie qualité, etc.) et autour des enjeux d’interopérabilité avec les autres données de l’entreprise. L’IA générative est alors un outil de génération de code qui peut être mis entre les mains de métiers peu familiers avec le développement technique : en ce sens, elle participe au processus d’acculturation.
- Amélioration de la sécurité et de la conformité : En développant la capacité d’interaction conversationnelle entre l’utilisateur et les outils de gestion de données, l’IA générative permet de fiabiliser les accès par type de domaine (génération d’attributs et d’outils d’authentification par utilisateur). Elle améliore également l’anonymisation des données et la classification par niveau de criticité.
- Enfin, l’IA générative peut aider à structurer le produit Data du point de vue du consommateur. En utilisant la donnée comme un contenu (au même titre qu’un texte, une image ou un fichier audio), l’IA peut générer un produit data plus complexe qui se structurera peu à peu jusqu’à former un actif échangeable. En cela, elle mobilise ses fonctions de conception et donc de créativité qui constituent la plus grande avancée de l’IA ces dernières années.