Synthetic persona simulations can be valuable tools for consumer research, but it is worth knowing when to benefit from them and when to be cautious of possible misleading outcomes.
As extracting insights from this wealth of information becomes increasingly complex, organizations are investigating AI tools, such as synthetic persona simulations, to accelerate research processes and test ideas and scenarios. Teams can have the possibility to rehearse business decisions, ideas, and concepts before implementation in a safe environment, thanks to the AI-generated user cohorts, created from real consumer data.
Beyond industry developments and initiatives, there is growing scientific investment across multiple institutions to define the field of synthetic personas and their use. For example, a 2024 research paper by Google DeepMind and a Stanford University-affiliated research team reported building 1,052 generative agents using two-hour qualitative interviews. They found that the agents matched participants' General Social Survey responses, and that participants matched their own responses two weeks later (Park et al., 2024).
Synthetic personas cannot accurately estimate market outcomes or replace real-life consumer research. They bring something different and important to the innovation cycles. When well-calibrated on rich qualitative data, these simulation models can generate convincing, falsifiable hypotheses at a higher speed by analyzing large volumes of data that influence product development cycles and create a competitive market advantage.
However, the speed, flexibility, and creative space that synthetic simulations deliver in research could create serious risks. Synthetic research simulations can produce convincing user stories but may overlook empirical consumer data and experience, especially when they lack explicit governance controls. All of those could lead to deficits and unreliable research outcomes.
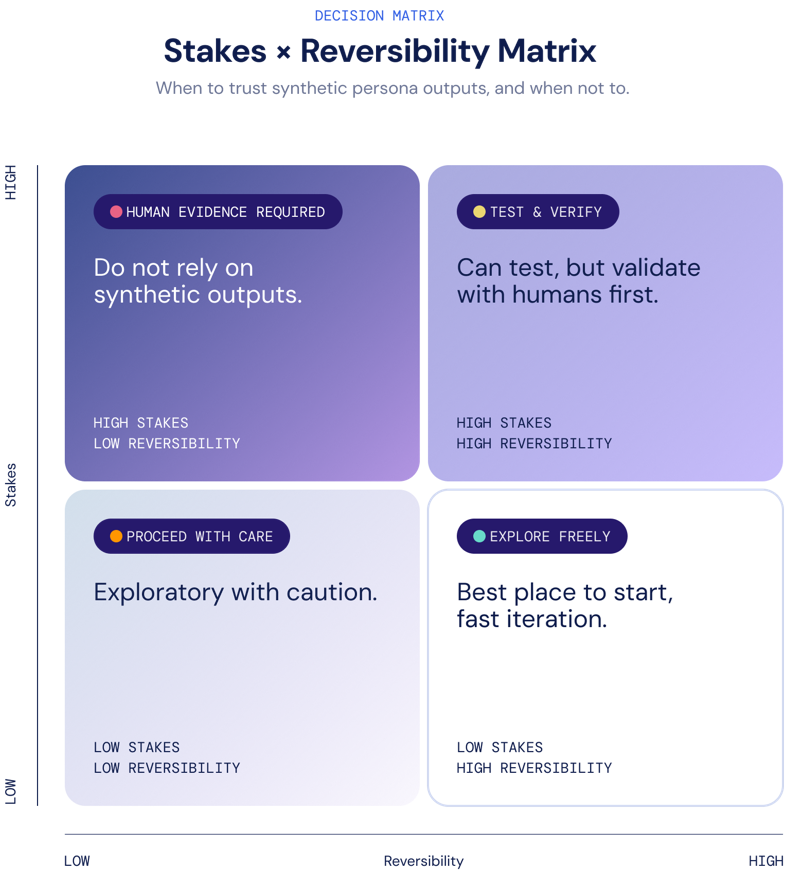
What Are the Risks and Governance Gaps of AI-Created Synthetic Persona Simulations for Executive Decision-Making?
Research shows that using synthetic personas can support experimentation and help companies close gaps in decision-making. However, to confirm the quality of these outcomes, we must ask: under what constraints can these studies remain valid decision-support tools rather than become persuasive fiction? Below are the three most common failure modes arising from synthetic consumer simulations.