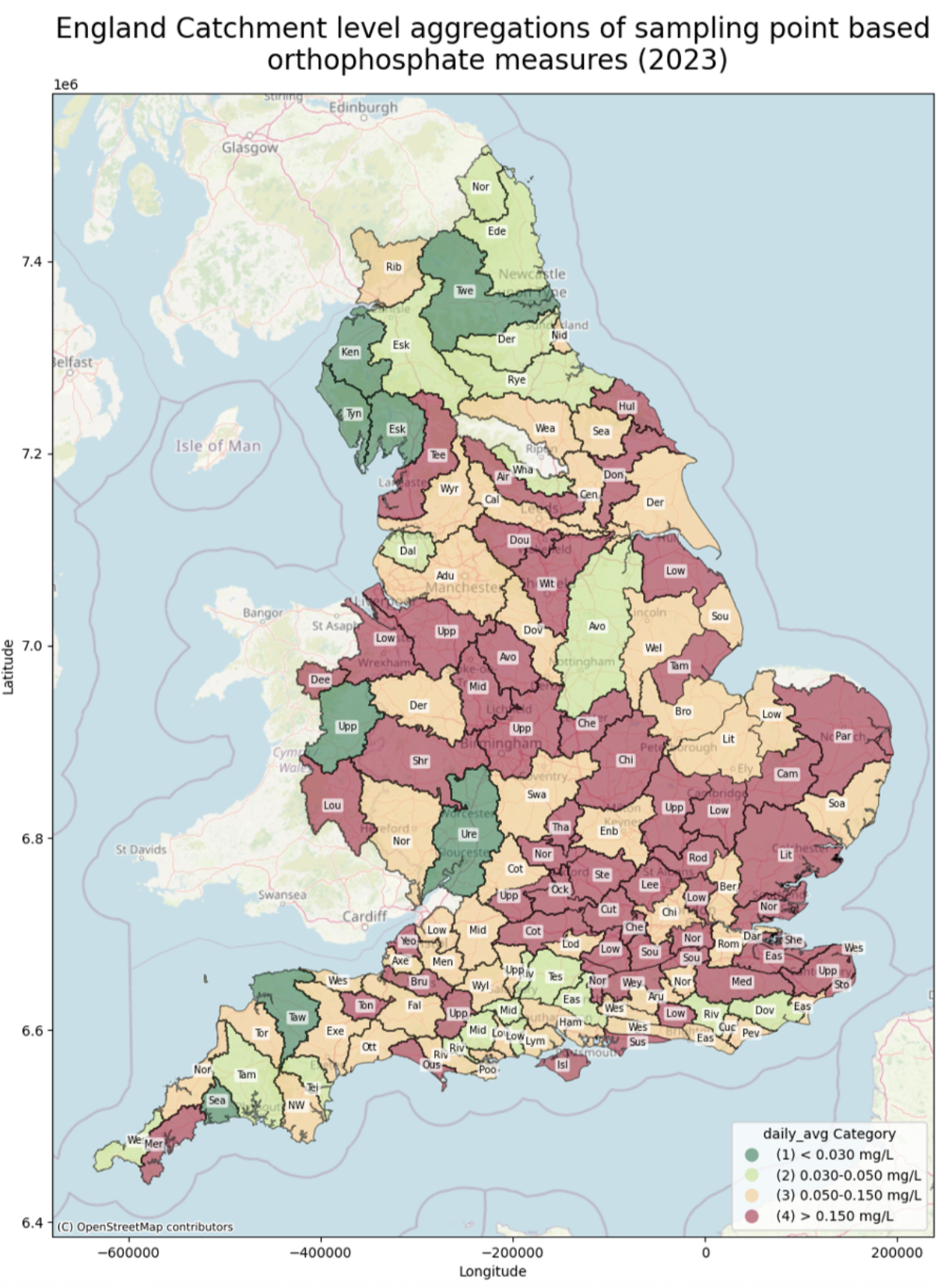
The current monitoring systems and limited data availability make it difficult to observe the fluctuations in orthophosphate over shorter periods of time, hindering effective identification of sources of nutrient pollution.
To address this gap, we have leveraged advanced artificial intelligence and machine learning (AI/ML) to develop an orthophosphate prediction model. While this model is not a conceptual representation of the underlying processes, it captures patterns and correlations in data that can supplement traditional scientific approaches. Its predictive capabilities enable both short-term forecasting and retrospective estimation, helping to fill in gaps resulting from limited monitoring. Furthermore, the relationships identified by the model may serve as a useful cross-check against conceptual water quality models, potentially revealing new hypotheses or validating existing assumptions about phosphorus dynamics.
Unlocking insights from decades of data
Our model harnesses 24 years of water quality data from the Environment Agency Water Quality Archive, encompassing over 70 million observations from more than 23,000 sampling points across 55 rivers. The dataset includes more than 3,000 physicochemical parameters – from pH levels to nutrient concentrations – and provides a holistic view of catchment dynamics. By training AI/ML models on these data, we can establish the relationships between these parameters and orthophosphate concentration.
To ensure accuracy, we have collaborated closely with domain experts from across the water sector to conduct extensive exploratory data analysis (EDA), uncovering patterns such as seasonal trends, rainfall impacts, and catchment-specific behaviours. Advanced techniques such as agglomerative clustering and K-Means++ segmentation identified groups of determinants influencing orthophosphate levels, while principal component analysis (PCA), SelectKBest, LassoCV, and f_Regression streamlined feature selection.
The modelling phase tested a suite of algorithms: traditional regression models (linear regression) for baseline insights, tree-based approaches (Random Forest, XGBoost, LightGBM) to capture non-linear relationships, artificial neural networks (ANN) for high-dimensional pattern recognition and Large Language Models (LLMs) such as ChemBERTa (built on RoBERTa), NIH Global chemical database, ChemDataExtractor and KMeans++ for segmentations.
We used advanced AI models, specifically, bidirectional transformers. These are AI models (such as BERT) that understand context by looking at words (or in this case, molecular features) in both directions. This allows the study of how molecules, such as certain environmental pollutants (determinands) and phosphates, are similar at a molecular level. Although this study has provided segmented results, it did not define clear boundaries between these segments. Therefore, we enhanced our analysis by using agglomerative clustering, which is more accurate in performing similarity analysis. For this analysis, we used NIH global chemical data base, RDKit and Cambridge ChemDataExtractor library. These models helped reveal which molecules are chemically attracted or compatible with each other. This understanding allowed us to improve our engineering methods and better connect large-scale environmental data with detailed molecular chemistry.
Since our first release (in June 2025), the Open Orthophosphate Model has undergone additional validation, to test how well it performs across a variety of catchment types. This includes testing the model in dry and wet catchments, catchments with a high base flow index, low base flow index, ‘near natural’ catchments (UK Benchmark) as well as urban and rural catchments. Across the different types of catchments, we have recorded a mean absolute error (MAE) ranging from 0.02 to 0.05 mg/L.
Furthermore, the model has been assessed using citizen science and continuous water quality data, to test how well it performs when using data outside of the EA water quality archive.
These validation exercises have helped pinpoint the strengths, limitations and opportunities for improvement of the current model. These outcomes and discussions about suggested next steps are detailed in the model output report released alongside the model in GitHub.
A collaborative and Open-Source approach
The overarching objective of River Deep Mountain AI is to bring key stakeholders involved in waterbody health together and collaboratively develop Open-Source AI/ML models that can inform effective actions to tackle waterbody pollution.
All our models will be released into the public domain to democratise artificial intelligence and benefit the entire water sector. The first iterations of our models were released in July 2025, and the second iterations are now being released
Access the second iteration of our Open Orthophosphate Model via GitHub.
River Deep Mountain AI is funded by the Ofwat Innovation Fund and consists of 6 core partners: Northumbrian Water, Cognizant Ocean, Xylem Inc, Water Research Centre Limited, The Rivers Trust and ADAS. The project is further supported by 6 water companies across the United Kingdom.