As part of River Deep Mountain AI, we are now releasing an early version of our open-source E. coli models on GitHub. Our models have the potential to transform how we monitor and forecast pollution in bathing waters using artificial intelligence.
England currently has more than 450 registered bathing waters that require E. coli testing periodically during summer periods to monitor contamination and to calculate annual bathing water classifications. Sampling and analysis for E. coli can be resource intensive, commonly resulting in a delay of 48 hours between sampling and the release of the results to the public. The delay, along with the infrequent sampling and the lack of E. coli testing during the winter season, increases the microbial health risk to swimmers, bathers, and other recreational waterbody users.
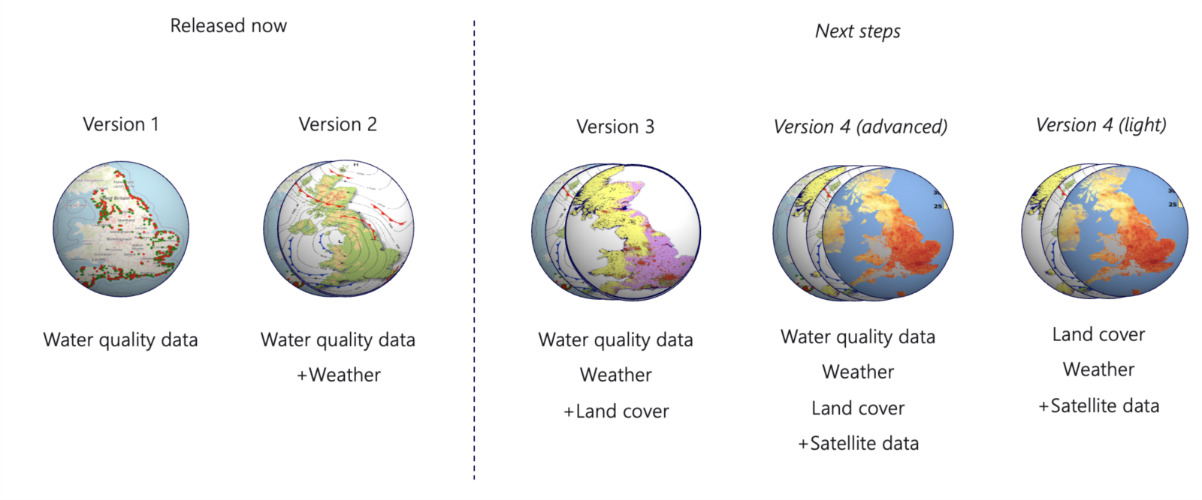
To tackle this challenge, we have developed our Open E. coli Models using 24 years of historical water quality data from across England (EA Water Quality Archive). The Open E. coli Models can be used as a support-tool for classifying the risk of E. coli contamination in bathing waters against a pre-defined threshold.
To ensure transferability between bathing waters, we have intentionally focused our model development on open-source datasets with national relevance, developing robust and general models for E. coli forecasting.
An AI model for short-term forecasting of E. coli in coastal bathing waters
Our Open E. coli Models compile historical information to identify trends and correlations between E. coli levels and other physical and chemical parameters in bathing waters. This allows the model to understand complex patterns that showcase a relationship with the increase of E. coli presence in the water. Additionally, meteorological (weather data) factors have been integrated, aimed at improving model accuracy. This model serves as a supportive decision-making tool for authorities, swimmers, water companies and more.
To build a robust general model, we have implemented extensive preprocessing, data extraction, correlation analysis, and feature engineering techniques to decide the best feature inputs. We have utilised multiple machine learning regression and classification models, including XGBoost, LightGBM, SVM, K-Nearest Neighbours and neural networks to assess and compare their superiority on the given tasks.