April 27, 2026
Why Your Multi-Agent Network Works in Demo but Falls Apart in the Wild

Why Your Multi-Agent Network Works in Demo but Falls Apart in the Wild
The shift from simple agent workflows to scalable systems introduces new challenges in coordination, integration, testing, and data management.
Over the past year, the way people build with AI has shifted in a meaningful way.
Instead of starting with architecture, APIs, and orchestration logic, you can start with intent. You describe what you want, refine it through iteration, and a working system begins to take shape. That shift with vibe coding has made it possible to stand up agent-based workflows in a fraction of the time it used to take, and in many cases without committing to rigid structure upfront.
It is not just faster but entirely changes how systems are designed. Teams are using it to prototype logistics workflows, automate internal processes, and explore new categories of applications without committing to rigid structure upfront.
What it has not done is remove the complexity that comes with running those systems once they move beyond that initial prototype phase. The moment those agent networks start interacting with real tools, real data, and real usage patterns, a different set of constraints begins to show up.
The system works once. Then it works again, slightly differently. Then a new edge case appears, a tool behaves unexpectedly, or an agent routes a task in a way that was never intended. Nothing is obviously broken, but the system is no longer something you can fully reason about.
What you are seeing at that point is not a bug – it is the transition from an agent to an agent operating system.
At Cognizant AI Lab, this is the problem we have been focused on with neuro-san, an open-source framework (Apache 2.0) for building multi-agent systems. The goal is not just to make agent networks easy to create, but to make them hold up once they start interacting with real tools, real data, and real usage patterns.
What we have found is that the same set of issues tends to emerge every time that transition happens. They are not tied to a specific use case or model, but rather they are structural.
1. Coordination stops being obvious
One of the reasons vibe coding feels so effective early on is that it removes the need to think explicitly about orchestration. You describe a task, and the system generates a network of agents with defined responsibilities, establishes how they communicate, and produces something that behaves coherently enough to validate the idea.
At that scale, the structure feels intuitive because it is still small enough to reason about directly. You can follow how a request moves through the system and understand why a particular outcome was produced.
That intuition does not hold as the system grows.
Once you move beyond a handful of agents, coordination stops being a matter of simple routing and starts becoming a property of the system as a whole. A single request might be interpreted differently by multiple agents, each operating with its own context and capabilities, and the question of who should act is no longer something that can be answered cleanly in one place.
Most implementations address this by introducing a central coordinating layer responsible for task distribution. Early on, this works well, providing a clear control point and making it easier to see how tasks are assigned when there are only a few agents.
Over time, however, that central layer accumulates responsibility. It needs to understand every agent, every tool, and every interaction pattern, and small changes elsewhere in the system often require corresponding changes in how orchestration is handled. What started as a simplifying abstraction gradually turns into a bottleneck, both in terms of performance and in terms of maintainability.
The approach we take in neuro-san reflects a different assumption, which is that coordination in a multi-agent system should not be owned by a single component at all.
Through Adaptive Agent-Oriented Software Architecture, or AAOSA, each agent evaluates incoming input and determines whether it can contribute to fulfilling the request. Instead of being assigned work, agents claim responsibility for the parts they understand, and those claims are then combined into a coordinated response.
This has practical implications as systems evolve. Adding a new agent does not require updating a central routing layer, because there is no single point that needs to be aware of everything. Agents remain modular, and coordination emerges from how they interact rather than from how they are instructed. This also extends across layers of the system, where groups of agents can coordinate within their own scope while contributing to higher-level workflows. It changes how ambiguity is handled as well. Instead of forcing a single interpretation early in the process, the system allows multiple agents to contribute and resolves those contributions collectively. As networks grow larger, that difference becomes increasingly important.
2. Tooling turns into infrastructure.
If coordination is the first place where complexity shows up, integration is the place where it accumulates.
In early-stage systems, connecting tools feels straightforward. You might wire in an API, connect a database, or add access to a knowledge base, and everything works well enough to demonstrate the value of the system. Vibe coding accelerates this by letting you describe integrations at a high level and letting the system fill in the details.
The difficulty is that these integrations rarely stay simple.
As systems grow, different agents require access to different tools, each with its own interface, authentication model, and data format. One agent might interact with a GitHub repository, another might query internal business systems, while a third pulls information from external services like Google Maps or a knowledge base. Each of these integrations introduces its own assumptions and its own failure modes.
Without a consistent way of handling them, integration logic becomes fragmented. It ends up scattered across prompts, scripts, and custom connectors, and over time the system becomes harder to extend because every new tool adds another layer of complexity.
At that point, integration is no longer a supporting detail. It is the system.
neuro-san approaches this differently by treating integration as a first-class concern through native support for the Model Context Protocol, or MCP. Rather than building one-off connectors, tools and services are exposed through a shared interface that agents can use consistently.
In practice, that means agents can interact with a wide range of systems in a uniform way, whether that involves reading from a GitHub repository, querying a knowledge base like DeepWiki, connecting to internal databases and APIs, or using external services such as Google Maps. As new tools are introduced, they can be added to the system without requiring existing integrations to be reworked.
The benefit is not just cleaner implementation. It changes how systems scale. Instead of accumulating bespoke connections, you build on a consistent layer that makes it possible to extend the system without increasing fragility.
3. Reliability becomes a question of behavior, not output
One of the more subtle shifts that happens as systems grow is how reliability needs to be evaluated.
In early stages, it is natural to judge a system based on whether it produces the correct output for a given input. If the answer looks right, the system is considered to be working. That approach breaks down quickly in multi-agent settings.
Large language models are inherently non-deterministic. The same input can lead to different reasoning paths, different tool usage, and different outputs. When multiple agents are involved, that variability compounds. A routing decision that changes slightly can lead to a completely different sequence of actions downstream.
What makes this challenging is that the system can still appear correct on the surface. It may produce plausible answers while quietly failing to follow the intended process or missing important constraints. Catching these issues requires a different way of thinking about testing.
Instead of validating individual outputs, you need to observe how the system behaves over time. That means running it repeatedly, measuring how often it produces the correct result, identifying where failures occur, and understanding how changes affect its behavior.
neuro-san includes a testing framework designed around this idea. It allows you to execute agent networks multiple times and evaluate consistency, accuracy, and performance across runs. Rather than relying on isolated examples, you get a clearer picture of how the system behaves under variation.
This is not just a tooling improvement. It reflects a shift in what reliability means in the context of agent systems.
4. Real agentic systems require control over data, not just access to it
The final set of constraints emerges when systems move beyond controlled environments and begin to interact with real data.
In early development, it is common to work with simplified inputs. That keeps iteration fast and reduces the risk of unintended behavior. In production, that abstraction disappears. Agents need to work with structured data, proprietary information, and often sensitive fields that cannot simply be passed through a language model.
At the same time, avoiding that data limits the usefulness of the system. Balancing these concerns requires separating how data is handled from how agents reason about it.
In neuro-san, this is addressed through a mechanism called sly_data, which provides a protected channel for passing structured or sensitive information between agents without exposing it directly to the model.
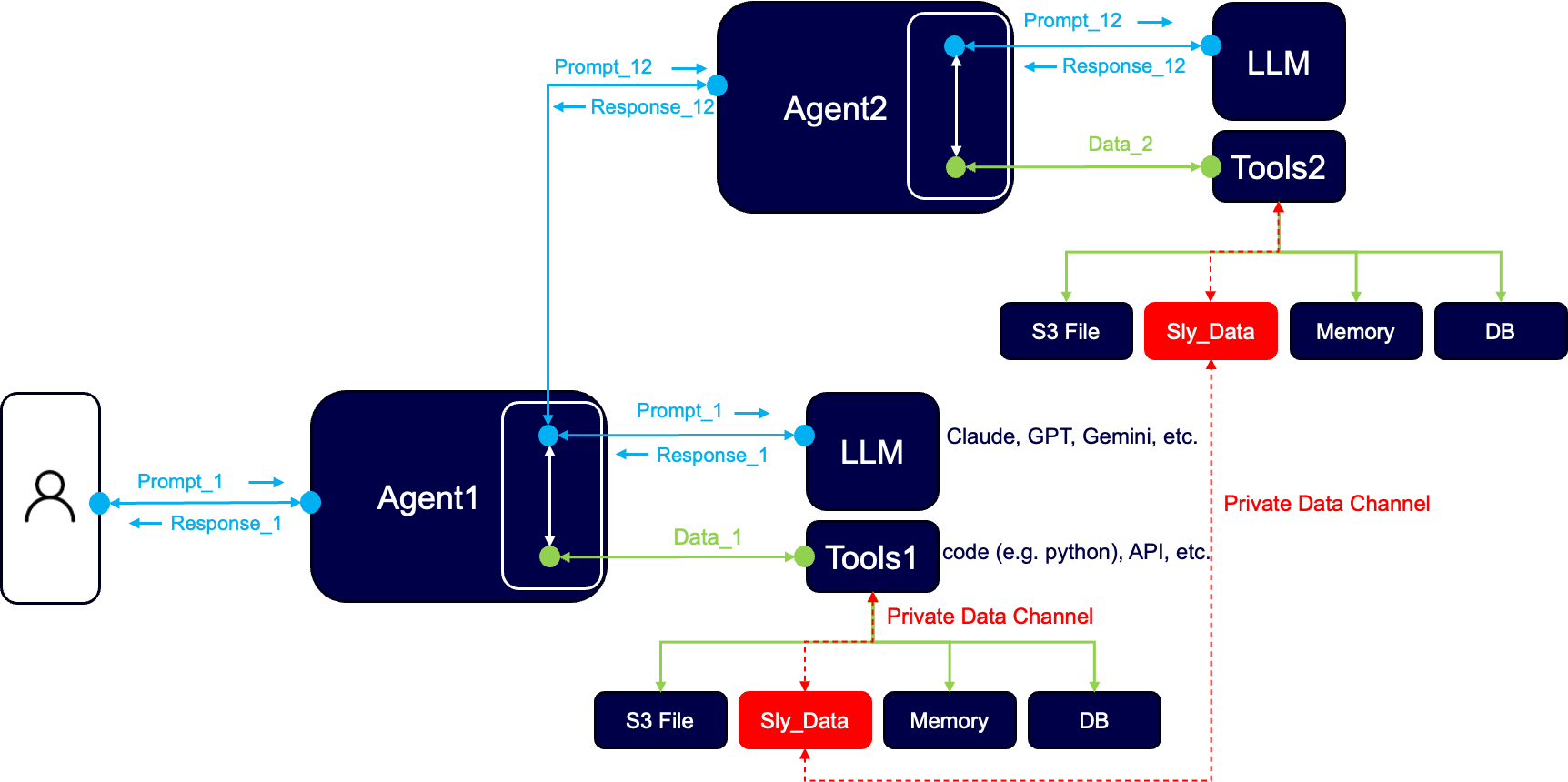
This allows the system to operate on real data while maintaining control over how that data is used and shared. It also makes data flows within the system more explicit, which becomes increasingly important as the number of agents and integrations grows.
As systems move beyond prototypes, this is no longer optional. It becomes part of the foundation.
From vibe coding to systems you can actually run
None of this replaces the value of vibe coding. If anything, it makes it more important.
The ability to start with intent, generate a working agent network, and refine it quickly is what makes this entire approach viable. In neuro-san, that workflow remains central. You can describe a system in plain language, and the platform translates that into a structured network of agents with defined responsibilities, communication paths, and access to tools. None of this replaces the value of vibe coding. If anything, it makes it more important.
What makes this useful is not just the initial generation, but what happens next.
The system is not fixed after it is created. You can continue to refine it directly, adding or removing agents, adjusting responsibilities, connecting MCP tools, or expanding the network as the scope evolves. These changes are structural rather than superficial. You are not just editing prompts, you are shaping how the system is composed and how it behaves.
This is where vibe coding starts to transition into system design. Once the initial network exists, the focus shifts from “can this work” to “will this keep working.” That shift introduces a different set of requirements.
The network needs to be tested repeatedly to understand how it behaves across runs, not just once. It needs to be grounded in real tools and services, not placeholder logic. It needs visibility into how agents communicate, so decisions can be traced and refined. And it needs to handle real data in a way that does not compromise reliability or safety.
neuro-san is designed to support that entire progression.
You can move from an initial, vibe-coded network to something that is iteratively refined, tested, and grounded in real integrations without rebuilding the system from scratch. The same structure that makes rapid prototyping possible becomes the foundation for something more durable.
That continuity is what tends to break in other approaches. The tools that make it easy to generate a system are often not the same ones that make it possible to run and evolve it. As a result, teams end up rebuilding once they move beyond the prototype.
The goal with neuro-san is to remove that break entirely, so the system you create is the system you continue to develop, test, and run.
What actually makes the difference
The shift from agents to agent operating systems is already happening, whether it is explicitly acknowledged or not.
As soon as agent networks start interacting with real environments, the same set of challenges appears. Coordination becomes harder to manage, integrations multiply, behavior becomes less predictable, and data handling becomes central to how the system operates.
These are not edge cases. They are the natural consequences of scale. What makes the difference is whether those constraints are treated as afterthoughts or as design inputs from the start.
neuro-san was built with the latter assumption. It keeps the speed and flexibility that make vibe coding useful, but extends it into something you can actually run, test, and evolve without the system becoming fragile.
If you are already building agent networks, you have likely run into some version of these issues. The question is not whether they show up, but how early you account for them.
You can explore neuro-san, experiment with building your own networks, and see how these ideas play out in practice here.