February 25, 2026
What Evolution Strategies for LLM Fine-Tuning Unlocked: Four New Research Directions

What Evolution Strategies for LLM Fine-Tuning Unlocked: Four New Research Directions
Evolution Strategies (ES) for LLM fine-tuning have emerged as a scalable, gradient-free alternative to reinforcement learning (RL) post-training. In this post, we outline four new research directions that expand the impact, applicability, and theoretical foundation of ES-based fine-tuning.
Reinforcement learning (RL) has become the dominant paradigm for fine-tuning large language models. It has enabled major advances in alignment and reasoning, but it also comes with significant tradeoffs. RL post-training requires complex reward pipelines, careful hyperparameter tuning, and substantial computational infrastructure. As models scale, these systems can become expensive to run, sensitive to instability, and prone to unintended behaviors such as reward hacking.
A few months ago, Cognizant AI Lab published groundbreaking research that challenged that dominance and quickly gained widespread attention.In that work, we introduced the first successful use of Evolution Strategies (ES) to fine-tune the full parameter set of large language models without backpropagation. ES was able to efficiently search over billions of parameters and outperform state-of-the-art reinforcement learning methods. It demonstrated:
Stronger sample efficiency
Greater tolerance to long-horizon rewards
Improved robustness across base models
More stable performance across runs
Significantly lower training cost
But the deeper impact of that breakthrough was not simply that ES worked at scale. It expanded the scope of what fine-tuning could target and where it could operate.
If large models can be adapted without gradients, what new kinds of capabilities and objectives become reachable? And if optimization is no longer tied to backpropagation, how far can fine-tuning extend across more complex tasks, different alignment goals, and even new hardware constraints?
Those questions directly shaped the next phase of our research.
Today, we are launching the second phase of our ES fine-tuning work: four new papers that each explore a distinct research direction made possible by the original breakthrough.
These directions span:
Expanding ES to more complex and structured reasoning domains
Improving metacognitive alignment in language models
Enabling fine-tuning directly in quantized, low-precision environments
Building a theoretical foundation for ES scalability in high-dimensional systems
Together, they demonstrate that ES fine-tuning is not a single breakthrough result, but an expanding research trajectory with growing practical applications and deeper scientific implications.
1. Expanding Evolution Strategies to More Complex and Structured Reasoning Domains
The first direction asks a straightforward but critical question: does ES remain effective as tasks become more structured, multi-step, and reasoning-intensive?
In the revised version of Evolution Strategies at Scale: LLM Fine-Tuning Beyond Reinforcement Learning, we extend our original work beyond the original countdown and conciseness tasks into substantially more challenging problem settings. Across multiple math reasoning benchmarks, ES remains competitive with state-of-the-art RL methods and shows generalization across datasets. We further evaluate structured puzzle domains such as Sudoku and ARC-AGI, where base models struggle significantly and ES fine-tuning produces clear improvements.
These results demonstrate that ES is not confined to narrow proof-of-concept tasks. It remains robust as a general-purpose framework for improving LLM reasoning while retaining its core advantages:
Gradient-free, inference-only training
Tolerance to long-horizon and delayed rewards
Reduced susceptibility to reward hacking
Stable optimization dynamics
Why this matters:
The original ES paper showed scalability. This work shows generality. By demonstrating strong performance across diverse and structured reasoning domains, it establishes ES as a viable general-purpose fine-tuning framework rather than a single benchmark success. That shift is critical for real-world adoption.
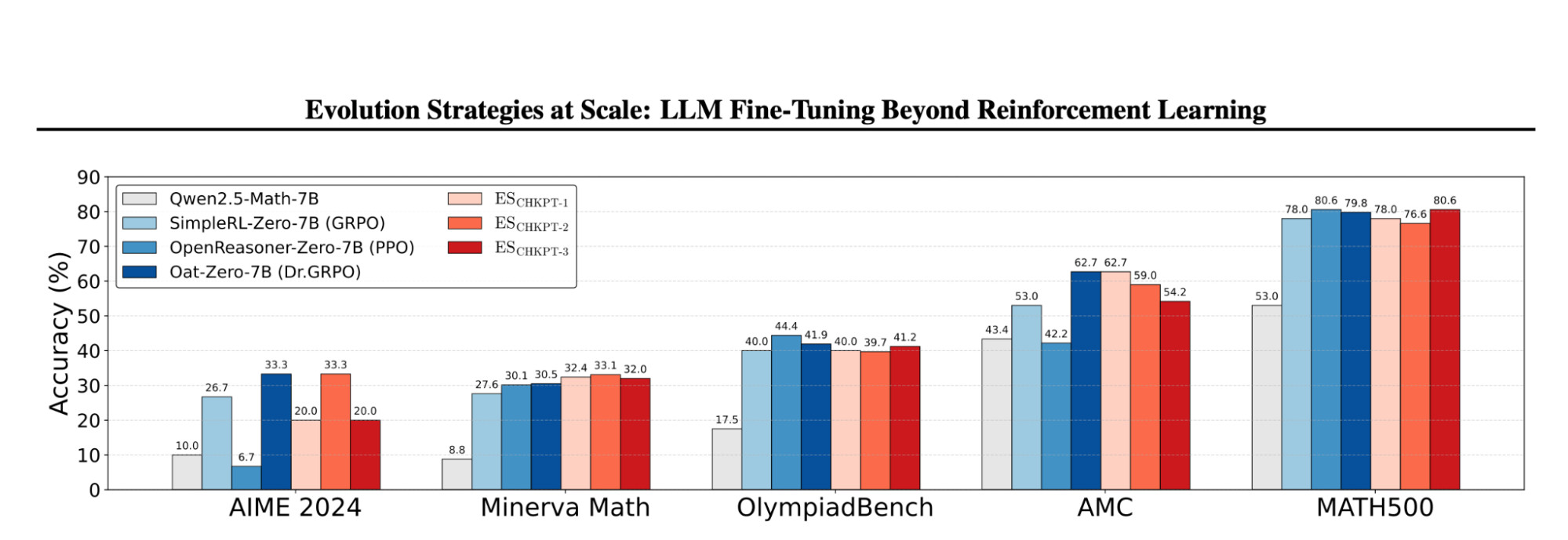
Figure 1. Performance of ES compared to established RL baselines across multiple math reasoning benchmarks. ES achieves competitive results, demonstrating strong generalization beyond the original proof-of-concept tasks.
2. Improving Metacognitive Alignment in Language Models
Performance alone is not sufficient for reliable AI systems. Models must also understand the limits of their own knowledge.
In Fine-Tuning Language Models to Know What They Know, we explore whether ES can improve metacognitive alignment — the consistency between a model’s answers and its confidence in those answers. Because this objective is difficult to formalize through traditional reward pipelines, it provides a natural testbed for gradient-free optimization.
Using Evolution Strategy for Metacognitive Alignment (ESMA), we demonstrate that ES-based fine-tuning reduces the overlap between confidence distributions for correct and incorrect responses across 1.5B, 3B, and 7B models. Confidence shifts higher for correct answers and lower for incorrect ones, indicating improved calibration and internal consistency.
This work also highlights a broader capability of ES: optimizing higher-level evaluation criteria that combine multiple signals without requiring differentiable reward structures.
Why this matters:
False confidence and hallucinations remain major obstacles to safe deployment of LLMs. Improving metacognitive alignment makes the models more reliable and trustworthy in real-world applications.
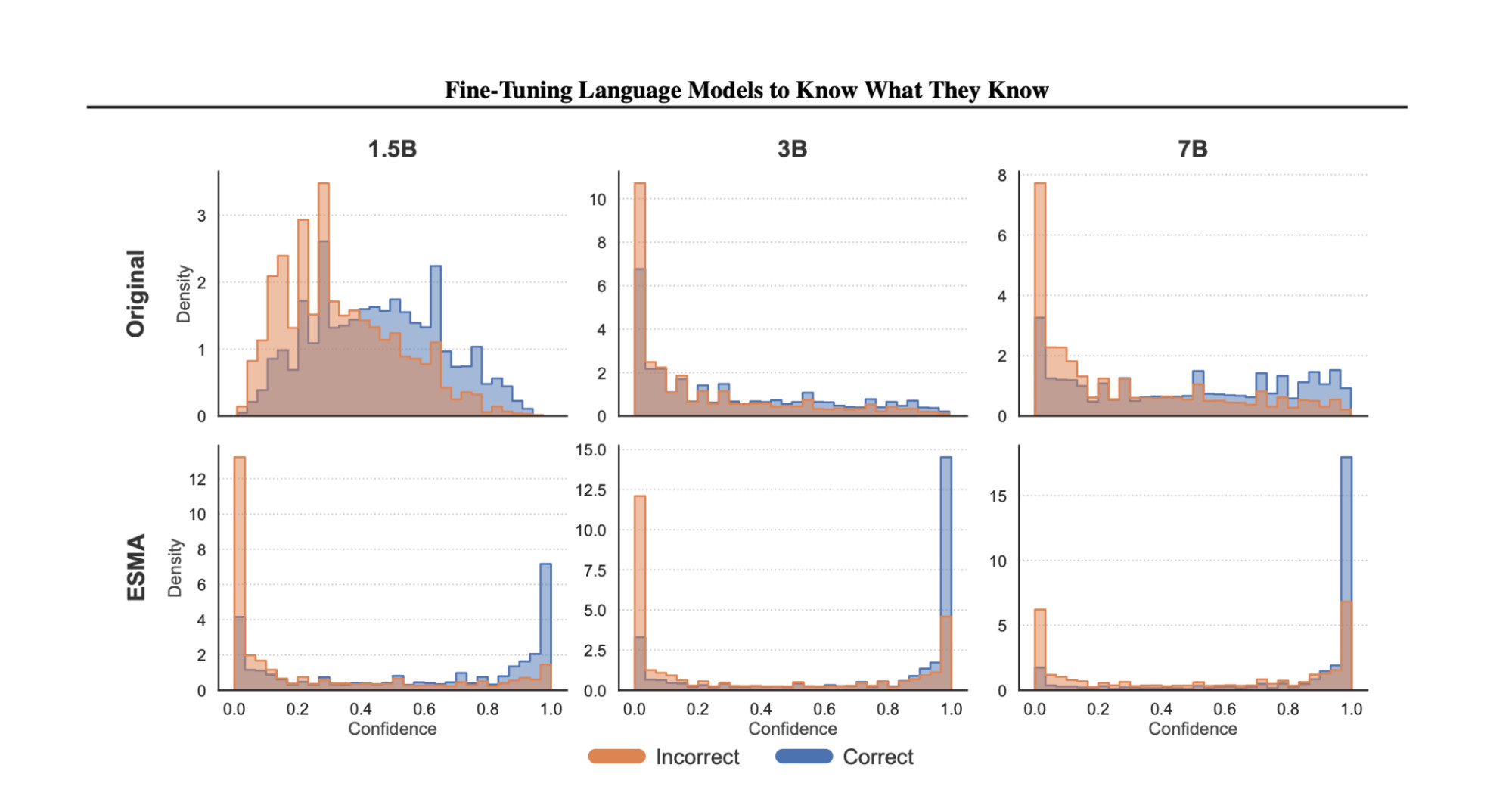
Figure 2: Confidence distributions for correct and incorrect responses across 1.5B, 3B, and 7B models. ESMA reduces overlap and shifts confidence higher for correct answers and lower for incorrect ones, reflecting improved metacognitive alignment.
3. Enabling Fine-Tuning in Quantized Environments
Quantization makes large models deployable. It also makes them difficult to adapt.
In Quantized Evolution Strategies: High-Precision Fine-Tuning of Quantized LLMs at Low-Precision Cost, we extend ES into discrete parameter spaces where backpropagation-based training is infeasible. By introducing accumulated error feedback and a stateless seed replay mechanism, Quantized Evolution Strategies (QES) preserve high-precision learning signals while maintaining a low-precision inference-level memory footprint.
This direction makes full-parameter fine-tuning possible directly within quantized models, combining the efficiency of low-precision deployment with the robustness of ES optimization.
Why this matters:
Quantized models are widely used to reduce hardware cost and energy consumption, but they are typically static after deployment. QES opens the possibility of adapting and improving quantized LLMs directly where they are needed.
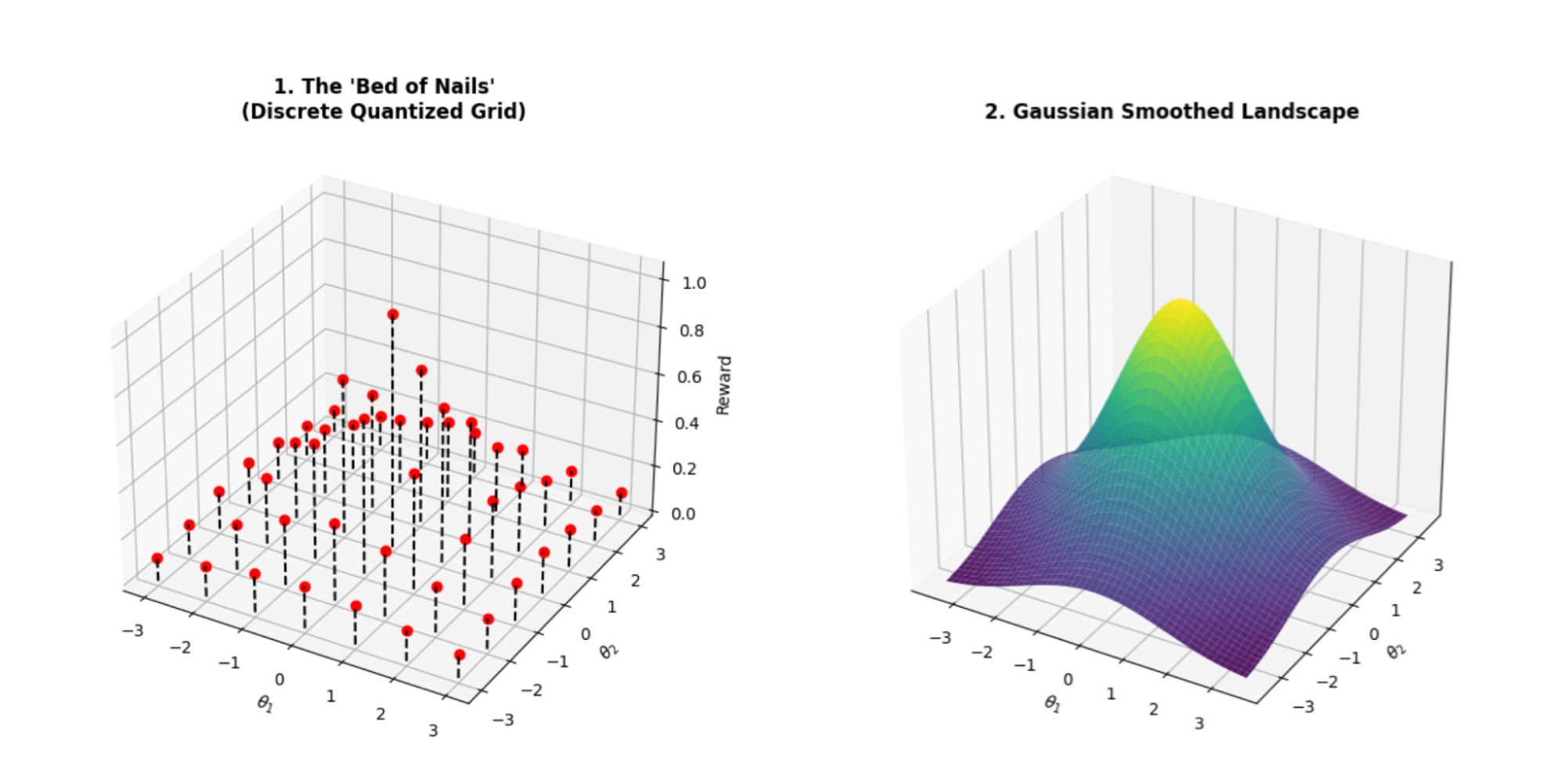
Figure 3: A continuous reward function versus its discrete grid version. In discrete space, updates can vanish or become inaccurate – the core challenge QES is designed to address.
4. Building a theoretical foundation for ES scalability
Finally, we turn to theory.
In The Blessing of Dimensionality in LLM Fine-Tuning: A Variance–Curvature Perspective, we investigate why ES can effectively search over billions of parameters using surprisingly small populations. The work explores the hypothesis that fine-tuning landscapes in large language models are low-dimensional in curvature, meaning only a small subset of parameter directions drive task performance.
Through empirical studies on toy systems and large-scale models, we find evidence supporting this geometric explanation. Rather than suffering from a curse of dimensionality, ES may benefit from structural properties of high-dimensional systems. By grounding ES scalability in a curvature-based perspective, this work moves the method from empirical success toward theoretical understanding.
Why this matters:
Understanding why ES scales is essential for predicting how it will behave at even larger model sizes. A clear theoretical foundation suggests that it is a viable approach as models continue to grow.
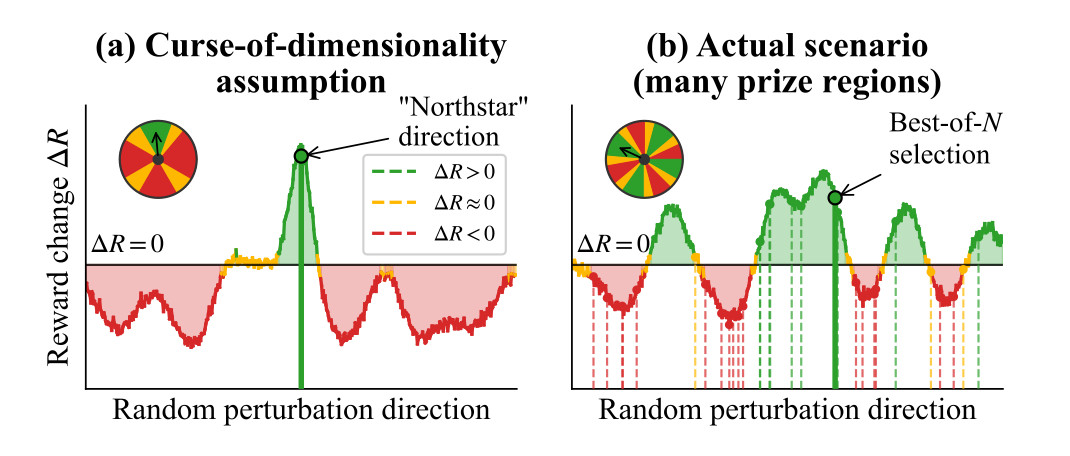
Figure 4: (a) In a “needle-in-a-haystack” setting, improvement lies in a single rare direction, making fixed-population search ineffective as dimension grows. (b) Under low-dimensional curvature, many perturbations align with a small active subspace, enabling ES to succeed with a small population.
From Breakthrough to Research Frontier
What began as a challenge to reinforcement learning has evolved into a broader expansion of how fine-tuning itself can be approached.
The original breakthrough demonstrated that billion-parameter models can be adapted without gradients, reducing cost and improving stability. The four directions introduced here explore the consequences of that shift: stronger reasoning performance across complex tasks, improved metacognitive alignment, adaptation under real-world hardware constraints, and a deeper theoretical understanding of optimization at extreme scale.
Together, they show that ES fine-tuning is no longer just an alternative optimization technique. It is emerging as a more flexible and scalable foundation for post-training – one that lowers training cost, broadens the types of objectives that can be optimized, and extends adaptation into environments where traditional methods struggle.
In the weeks ahead, we will examine each of these papers in greater depth, sharing the technical insights and experimental findings behind this next phase of ES fine-tuning research.

Xin is a research scientist that specializes in uncertainty quantification, evolutionary neural architecture search, and metacognition, with a PhD from National University of Singapore