February 11, 2025
Single Agent vs. Multi-Agent: Choosing the Right Architecture

Single Agent vs Multi-Agent: Trade-Offs, Efficiency & Control
A discussion on the trade‑offs between monolithic single‑agent models and modular multi‑agent systems, exploring efficiency, reliability, and control in agentic AI design
I wonder what you think about this emerging dichotomy in Agentic approaches between those who are building a single agent to rule them all, like OpenAI’s Operator or their more recent DeepResearch, versus those who are building custom, engineered, multi-agent solutions for similar use-cases?
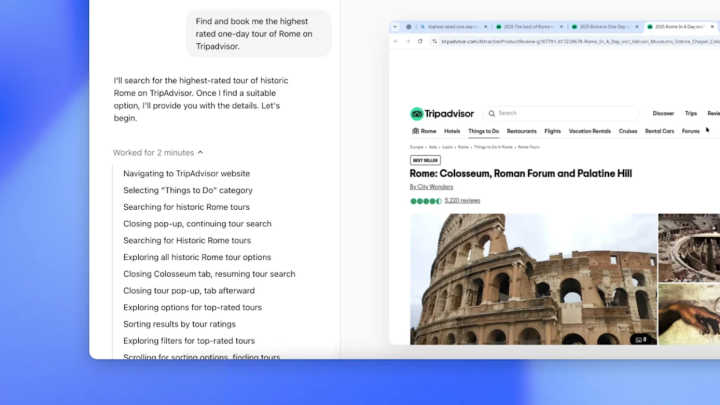
Figure 1. OpenAI’s Operator
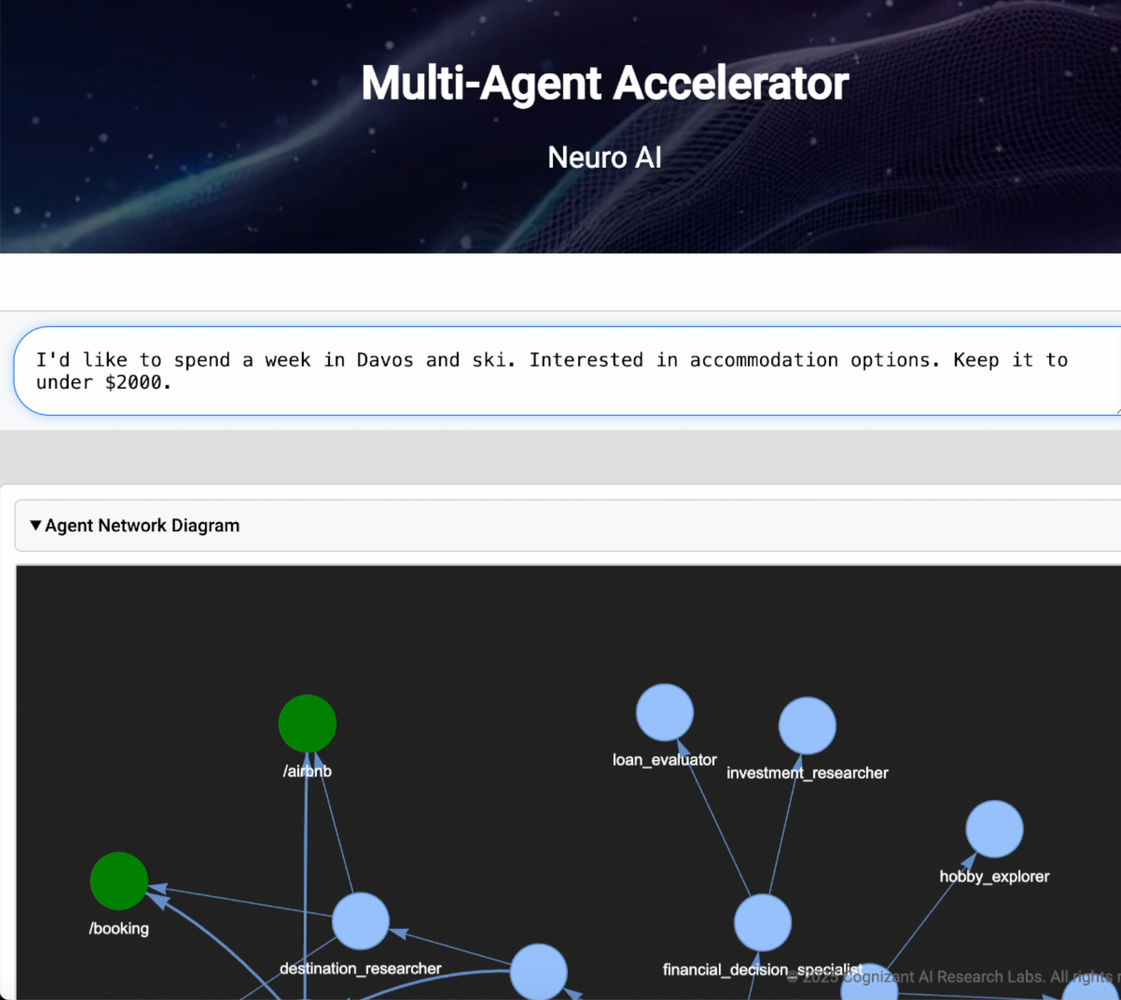
Figure 2. A Multi-agent consumer decision assistant
I can see why commercial LLM companies like OpenAI and DeepMind, whose vision has always been the construction of “AGI”, would tend towards monolithic, all-powerful large models as agents, but is it practical?
Modularity has always had inherent appeal to me. I feel like the moment we move from using models (e.g., LLMs) to using LLM-based Agents, we are entering engineering territory, where the job description of the agent, and the selection and implementation of its tools depend very much on the use-case, and modularization, with its benefits (reuse, specialization, and divide and concur), is well suited for engineering work.
The manner by which single-agent systems are being fine-tuned on Chain of Thought reasoning (CoT) is useful for certain agentic tasks requiring reasoning or coding, but it does seem to bind the agent to a certain average reasoning behavior that reduces its general applicability. In using reasoning models for coding, I’ve often noticed that these systems get stuck into a certain manner of “thinking” and start repeating themselves. In fact, a heuristic I’ve resorted to often is to have the reasoning model (such as OpenAI's o1) come up with a first pass, but then, if it gets anything wrong, to follow up with a non-reasoning models (like GPT-4o), and this seems to get the model unstuck, allowing it to explore alternatives.
I therefore don’t think there is a one-size-fits-all LLM for all agents. This becomes even clearer when you think of the flexibility to use smaller more specialized LLMs for more specialized agents. This gives us the option to run some agents on-prem, for example in settings where there are sensitive data considerations.
Another practical consideration that makes us lean towards multi-agent systems is interoperability. Many businesses are promoting their own agents and enterprises will want to connect these agents to each other, or to proprietary ingrown agents.
You can also fine-tune LLMs depending on their job description within the larger multi-agent system. Simply collect and label data specific to an agent’s behavior and fine-tune for each agent separately. How would you do that with a single agent that is meant to do everything?
Context size is still a limiting factor for LLMs. Even with LLMs that can take a relatively large number of tokens as input, staying faithful to everything that is stated in the context is proving to be a challenge. In agentic systems, the system prompt, dialog history, memory, and tool descriptions all take valuable context tokens. All these elements are reduced as we limit and focus the responsibility of individual agents within a multi-agent system. If we are smart about memory and dialog history, we can afford to be much more selective and specific about how we use an agent’s context, making agents more reliable and predictable in their behavior.
Then there’s the question of performance. Is a single LLM-Agent more efficient than the equivalent multi-agent system? Our lab recently coauthored a position paper arguing for how more refined decomposition into agents is critical for (at least) efficiency at scale. There’s even some evidence that scaling laws analogous to those in neural network which resulted in the amazing emergent behavior in LLMs are also exhibited in multi-agent systems, and we are talking cooperation among more than 1000 agents here.
Finally, there is a more fundamental question behind this choice between human engineered systems of AI Agents, versus Autonomously AI-Engineered systems: Where do we, as humans, exert our control and design? Or are we just simply expressing intent and leaving the rest to the LLM?
The answer is not as obvious as our initial intuition. We are building increasingly intelligent systems that, in many ways, are already smarter than us. Would we rather have a less intelligent system (us humans) design and set up more intelligent systems (AI Agents)? We are already seeing spectacular performance by large reasoning models on benchmarks many of us would have a very hard time acing. Isn’t it time for us to defer to these models as the artificial brains for handling all aspects of a system’s operations? Let’s just give all the APIs for a system to a single very powerful LLM and let it decide how and when to use them. Afterall, we are still in charge because we are expressing our intent as input to the agent.
Not so fast. There are fundamental limitations to our state of the art in AI, which should give us pause here. Our LLMs have a hard time knowing what they don’t know (and for that matter, they also have a hard time knowing what they do know). In other words, they are lacking meta-cognition, something that seems to come quite naturally to us, perhaps because our brains are wired differently than a feed-forward, train-once, run many times, LLM.
Also, while seeing AI generated artwork, prose, or even poetry does demonstrate incredible creativity by LLMs, another paper we recently coauthored shows how current ML and reinforcement learning methods have a hard time dealing with the unexpected effects of creative actions, or what is commonly referred to as ‘unknown unknowns’.
I don’t think these limitations are easy to overcome, unless we rethink our approach to AI or we have some major breakthroughs.
Multi-agent systems allow us to engineer safeguards for such limitations. Rather than potential magnification of risky behavior and inconsistencies due to relying solely on a single monolithic LLM-Agent, we can build resilience in distributed, modularized, redundant, multi-agent systems. These systems can have built-in agentic checks and balances as well as safeguards, including rule-based and human fallbacks. Additionally, the multi-agent approach allows us to build and extend systems incrementally, testing and fine-tuning various agents in isolation and within a sandboxed larger system, before plugging them into the live agent network. It also provides room for regulators of responsible AI to mandate the use of third-party agents for more critical and risky operations.
Having said all of this, I feel like I have always been inclined towards multi agenthood and so I have a feeling that I’m not quite seeing the other side of this argument clearly due to my bias for encapsulation and modularization.

Babak Hodjat is the Chief AI Officer at Cognizant and former co-founder & CEO of Sentient. He is responsible for the technology behind the world’s largest distributed AI system.