
March 11, 2026
Can Language Models Know What They Know?

Training Metacognition in Language Models with Evolution Strategies
A new Cognizant AI Lab paper explores AI metacognition and shows how Evolution Strategies can improve a model’s ability to distinguish knowledge from guesswork.

Modern language models contain vast amounts of knowledge, yet their ability to recognize the limits of that knowledge remains largely unexplored.
A model may produce the correct answer while failing to recognize that it knows it. It may also claim to know something and then answer incorrectly. In both cases, the connection between what the model knows and what it believes it knows becomes unclear, revealing a fundamental gap in how language models relate to their own knowledge.
Humans routinely manage this distinction through metacognition. We recognize when we are certain about an answer, when we are unsure, and when we simply do not know. This ability plays a central role in reasoning, learning, and decision-making. It helps us avoid overconfidence, seek additional information when needed, and communicate uncertainty appropriately.
For AI systems, this ability is increasingly important. As language models move into research workflows, enterprise tools, and decision-support systems, their usefulness depends not only on the knowledge they contain, but also on their ability to recognize the limits of that knowledge. When a system cannot reliably distinguish between knowledge and guesswork, it becomes harder to trust its outputs, harder to know when to rely on its answers, and more likely to produce hallucinations or misplaced confidence in critical settings.
This raises a fundamental question: do language models actually know what they know?
At Cognizant AI Lab, in collaboration with a researcher at UT Austin, we set out to study that question directly in our new paper, Fine-Tuning Language Models to Know What They Know.
The work introduces a new way to measure metacognition in language models and explores whether that ability can be improved through training.
Measuring Metacognition in Language Models
To understand whether language models can recognize their own knowledge, we first need a way to measure that ability.
Research in psychology and neuroscience often studies human metacognition by comparing performance and self-assessment. Participants answer a question and then report whether they believe their answer is correct. The relationship between these signals reveals how well a person can monitor their own knowledge.
This paper adapts that idea to language models through a dual-question evaluation framework.
For each question, the model is asked the same underlying query in two independent ways:
Direct Question: the model provides the answer
Meta Question: the model is asked whether it knows the answer
For example:
Direct:
Q: What is the capital of the United States?
A: New York.
Meta:
Q: Do you know the capital of the United States?
A: Yes, I know.
These prompts are issued independently so the model’s self-assessment cannot depend on the text it already produced.
To quantify the relationship between correctness and self-assessment, the study uses Type 2 d', a metric widely used in human metacognition research. This metric measures how well an agent can distinguish between situations where it is correct and situations where it is incorrect.
In other words, it measures whether the model’s self-reported knowledge actually reflects its underlying knowledge state. This distinction is critical. For example, if a model randomly answers “I know” or “I don’t know” to questions with a 50% accuracy rate, a simple alignment calculation might incorrectly evaluate its metacognitive ability as 50%. The type 2 d' metric avoids this issue by measuring the meta-answer’s ability to distinguish between the correct and incorrect responses, providing a clearer view of the model’s true metacognitive ability.
What Today’s Models Reveal
Applying this framework to existing language models reveals a consistent and somewhat surprising pattern.
Many off-the-shelf LLMs exhibit weak metacognitive sensitivity. Their answers may be correct, but their self-assessments often fail to track whether those answers are actually reliable. Models sometimes claim to know something and then produce an incorrect answer. In other cases, they say they do not know even when they are capable of generating the correct response.
These behaviors indicate that the relationship between knowledge and awareness of knowledge is often loosely coupled. The model may contain the information required to answer a question, but it does not reliably recognize when that information is present.
The experiments show that larger and more advanced models generally display somewhat better alignment, but the gap remains significant. Even strong models frequently misjudge their own knowledge state, demonstrating that metacognitive ability does not automatically emerge from scale alone.
This observation reinforces the core insight motivating the study: improving the reliability of AI systems may require not only improving what models know, but also strengthening how they track and report that knowledge.
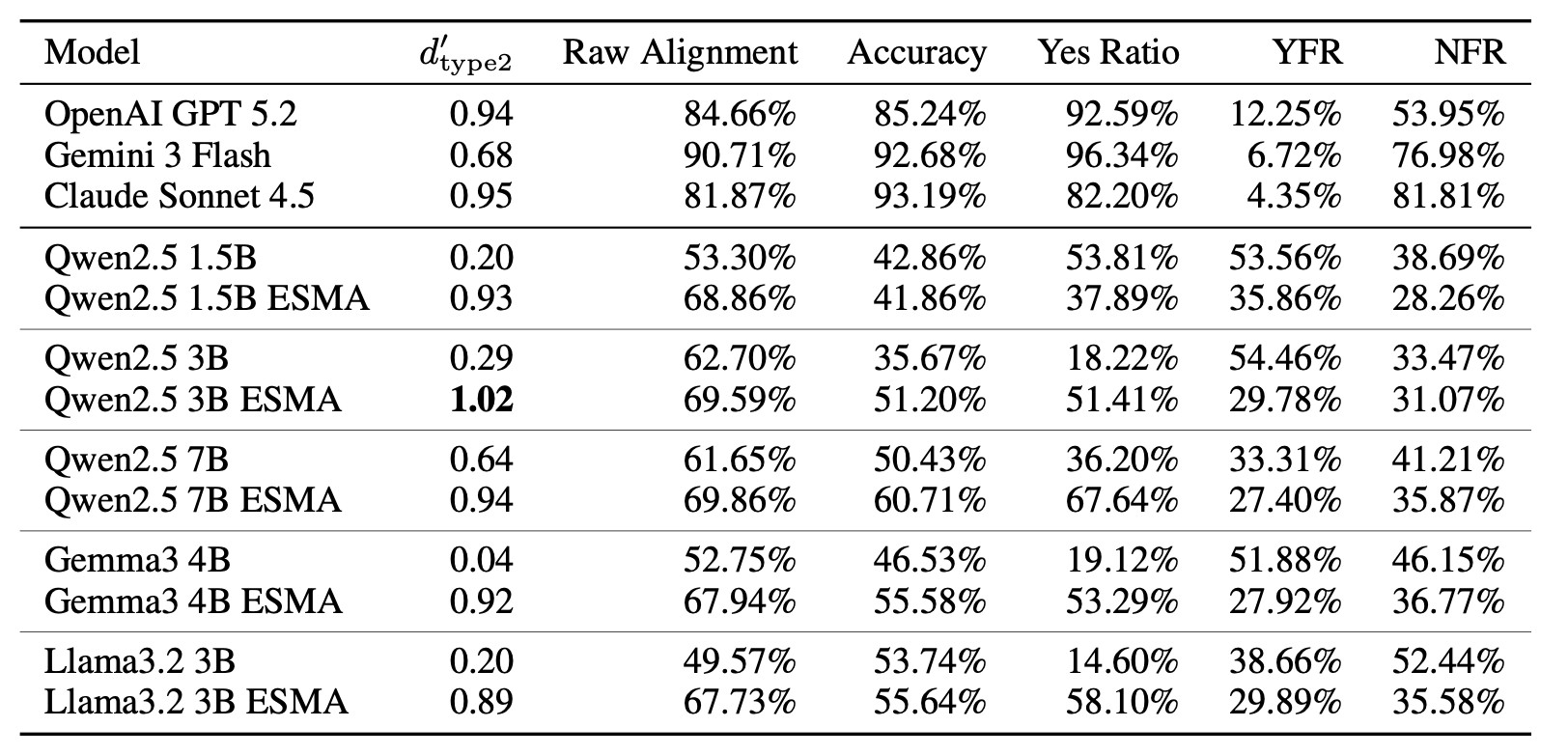
Table 1. Metacognitive abilities of various base LLMs and their ESMA fine-tuned versions. This comparison shows that baseline models often exhibit low metacognitive sensitivity (low type 2 d), while ESMA significantly improves alignment between correctness and self-assessment.
Why This Requires a Different Optimization Approach
Once the gap between knowledge and self-awareness is identified, the next challenge is improving it.
At first glance, this might appear to be a standard fine-tuning problem. However, the objective introduces an unusual difficulty. Metacognitive alignment depends on the relationship between two independent interactions with the same model: answering a question and assessing whether the model knows the answer.
Traditional gradient-based training methods typically optimize outputs within a single sequence. In contrast, metacognitive alignment depends on behavior across multiple contexts, making it difficult to assign gradients that capture the desired relationship between answers and self-assessments.
This is where Evolution Strategies (ES) become particularly useful.
Evolution Strategies are gradient-free optimization methods that explore parameter space directly. Instead of computing gradients, ES generates variations of a model, evaluates their behavior, and updates parameters based on outcome-level rewards. Because the method only requires a scalar reward signal, it can optimize objectives that depend on holistic behavioral patterns, including those that emerge across multiple independent prompts.
This property makes ES well suited for training objectives that are difficult or impossible to express through conventional gradient-based optimization.
Evolution Strategies for Metacognitive Alignment
To address the metacognition problem, the paper introduces Evolution Strategies for Metacognitive Alignment (ESMA).
The process begins with a base language model. Multiple variants of the model are created by adding small random perturbations to its parameters. Each variant is evaluated using the dual-question framework, receiving a reward based on two factors:
Whether the answer to the direct question is correct
Whether the model’s self-assessment correctly reflects that outcome
Variants that better align knowledge and self-assessment receive higher rewards and contribute more strongly to the next generation of models. Through repeated iterations, this evolutionary process gradually shifts the model’s parameters toward configurations that produce stronger metacognitive alignment.
Importantly, the reward balances two objectives: maintaining factual accuracy while encouraging correct meta-level reporting. This prevents degenerate solutions where a model might maximize alignment simply by refusing to answer questions.
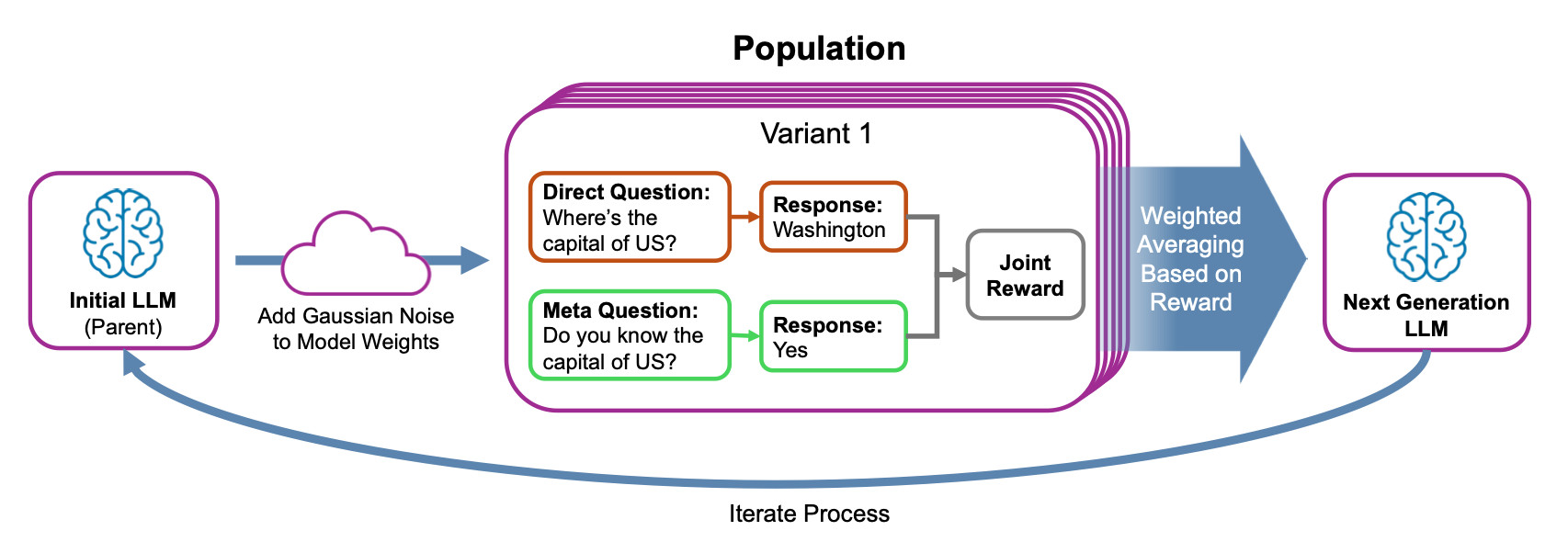
Figure 1. Overview of Evolution Strategy for Metacognitive Alignment (ESMA). The process begins with an initial parent LLM, whose weights are perturbed with Gaussian noise to create a population of model variants. Each variant is evaluated on a dual-axis task: a Direct Question, which tests factual knowledge, and a Meta Question, which tests self-knowledge. A joint reward is calculated based on the alignment between correctness and the meta response, and the next-generation LLM is produced by weighted averaging based on reward.
Learning to Know What It Knows
The results show that ESMA can significantly improve metacognitive ability across multiple open-weight language models.
Across several model families, the metacognitive sensitivity metric type 2 d' increases dramatically, often reaching values around 1.0, which corresponds to moderate discrimination in cognitive science experiments. In some cases, smaller open models trained with ESMA achieve metacognitive performance comparable to or exceeding that of much larger systems.
Beyond these improvements in the training setup, the models also demonstrate strong generalization. Even though ESMA training focuses on a single metacognitive task, the resulting models maintain improved alignment across different datasets, languages, prompt formats, and evaluation settings. The improvements also persist when models express their knowledge through continuous confidence scores rather than simple yes-or-no responses.
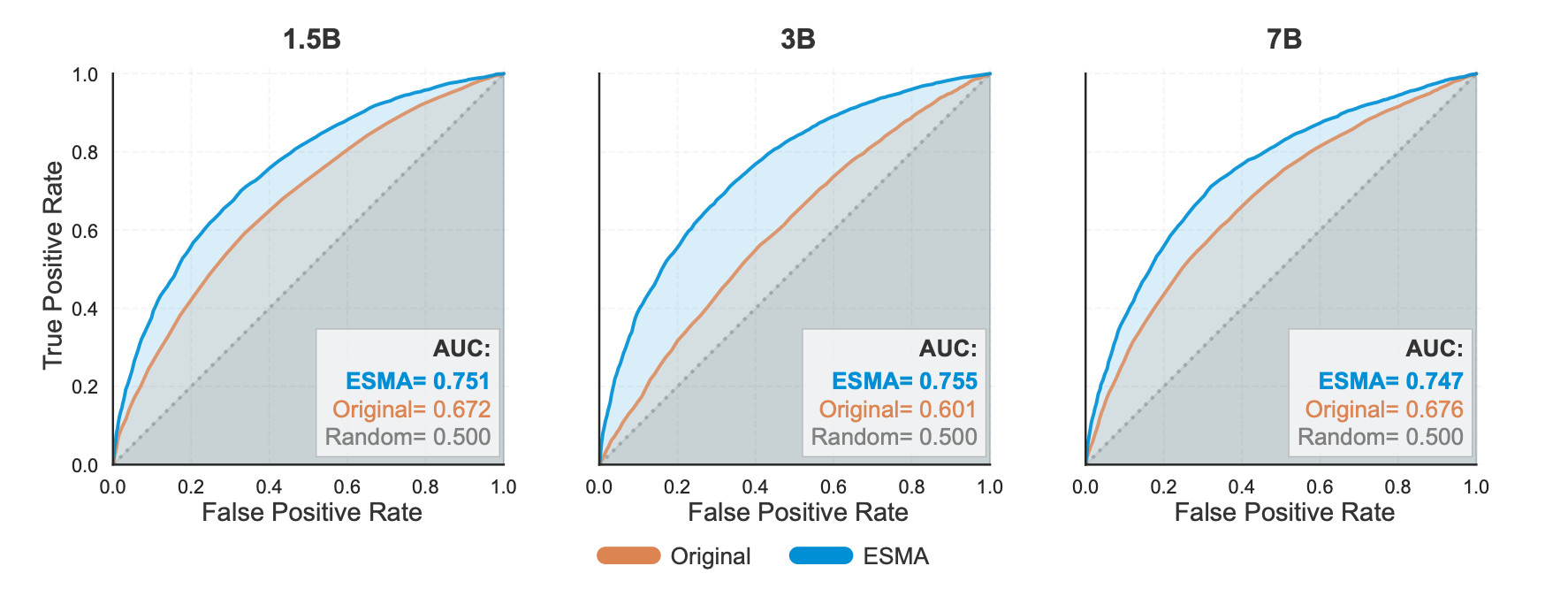
Figure 2. Type-2 ROC curves showing improved metacognitive sensitivity after ESMA training. The plots compare original and ESMA models using continuous confidence scores. ESMA consistently improves metacognitive sensitivity across the 1.5B, 3B, and 7B Qwen2.5 models, with AUC values moving to roughly 0.75, indicating stronger discrimination between known and unknown information.
Visualization of the models’ confidence distributions reveals a clear structural shift. After ESMA training, correct answers tend to cluster near high-confidence regions while incorrect answers move toward low-confidence regions, indicating that the models have developed a more consistent internal signal for distinguishing known from unknown information.
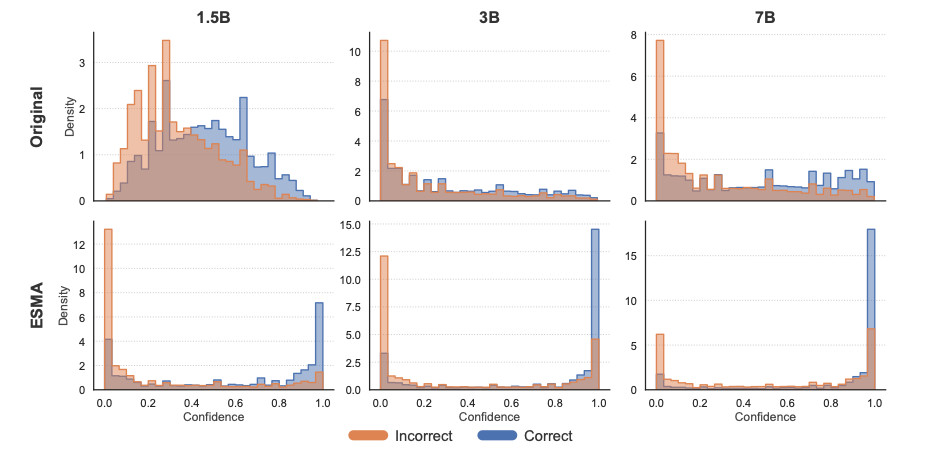
Figure 3. Distribution of metacognitive confidence by correctness across model scales. Confidence distributions for correct and incorrect answers across Qwen2.5 models (1.5B, 3B, 7B). After ESMA training, correct responses concentrate near high confidence while incorrect responses shift toward low confidence, reducing overlap and indicating stronger metacognitive separation.
Why This Matters
Metacognition is more than a theoretical property of intelligence. It plays a practical role in building reliable AI systems. Models that can recognize the limits of their knowledge are better able to abstain when appropriate, avoid hallucinations, and request additional information. These behaviors are essential as AI systems move into high-stakes domains where incorrect or overconfident responses can have significant consequences.
Beyond these immediate utilities, metacognition is a fundamental component of the higher cognitive functions required to reach AGI. To achieve this level of autonomy, an agent must identify what it does not know or cannot perform. It must be capable of seeking help or accumulating new knowledge to resolve these gaps. Furthermore, an agent needs the ability to perform surgical updates to its internal state as information changes, or track the provenance of its knowledge to resolve contradictions based on source reliability.
This work also highlights a unique advantage of Evolution Strategies as a training paradigm. Traditional gradient-based approaches often struggle to capture interrelated behavioral patterns that manifest across independent contexts. Because ES optimizes outcome-level behavior, it can target these high-level patterns directly as a goal. This makes it particularly well-suited for training higher-level cognitive properties where the relevant signals emerge only when behavior is observed across multiple interactions.
By leveraging the strengths of ES, this research points toward a future where we can directly optimize higher-order targets. Strengthening the alignment between knowledge and self-awareness is a step toward language models that do not just retrieve information but actively manage their own intelligence.

Elliot is a research scientist who is oriented around improving creative AI through open-endedness, evolutionary computation, neural networks, and multi-agent systems.