October 28, 2025
Evolution Strategies vs Reinforcement Learning: A New Fine-Tuning Approach for LLMs

Evolution Strategies vs Reinforcement Learning: A New Fine-Tuning Approach for LLMs
A new approach from Cognizant AI Lab challenges reinforcement learning as the default for LLM post-training

Fine-tuning is essential for every modern large language model. GPT, Claude, LLaMA, DeepSeek, Qwen – all of them are trained first on massive amounts of general data, then fine-tuned to further elicit reasoning capability or become better aligned with human intent.
Reinforcement learning (RL) is currently the primary choice for such fine-tuning. Techniques like PPO and GRPO dominate the field and have shaped nearly every production-grade LLM in use.
But RL comes with known limitations. It struggles with sparse, long-horizon rewards. It's sensitive to model initialization and hyperparameter choices. And without careful constraints, it’s prone to reward hacking, leading to undesirable behaviors.
We explore a long-standing but largely overlooked alternative to reinforcement learning: evolution strategies (ES). Earlier work from OpenAI and Uber demonstrated the promise of ES on control and optimization problems. However, in our paper, we present the first successful use of ES to fine-tune the full parameter set of large language models, including models with billions of parameters. The results show that ES can outperform state-of-the-art RL methods on key dimensions such as sample efficiency, tolerance to long-horizon rewards, robustness to different base LLMs, less tendency to reward hacking, and more stable performance across runs.
This approach is not just an optimization tweak. It represents a new direction for how we fine-tune LLMs at scale and points toward simpler, more reliable, and more adaptable post-training techniques for future generations of AI systems.
A scalable framework for full-parameter fine-tuning using ES
Prior work using evolution strategies typically limited the model size (up to millions of parameters) or reduced optimization dimensionality, such as tuning only the output layer or adapters. This new approach instead scales ES to full-parameter fine-tuning of transformers with billions of parameters, without relying on gradients or backpropagation.
The method uses an algorithmically simplified but engineeringly optimized ES variant. Through memory-efficient and traceable parameter perturbations, it enables distributed evaluations (inferences) while significantly reducing GPU memory usage and communication overhead. By design, this makes ES viable for large-scale LLMs while preserving the simplicity and robustness of gradient-free optimization.
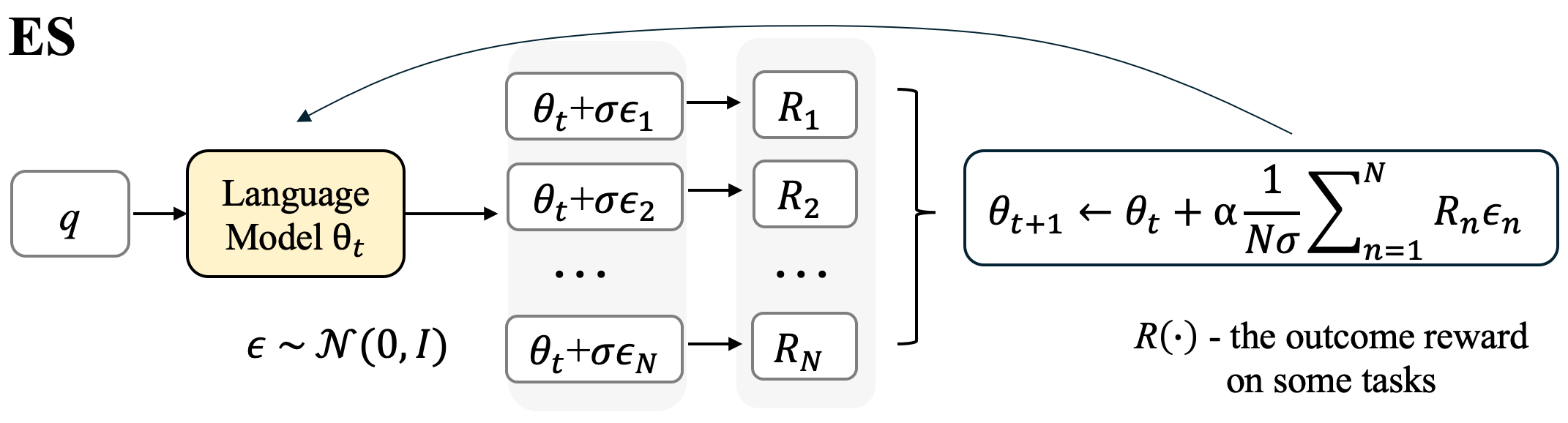
Figure 1: Flow chart of ES fine-tuning.
ES explores by directly sampling perturbations (ϵ) in the parameter space (θ). The perturbed models are evaluated (performing inferences) for outcome-only rewards (R), which are used to form the aggregated parameter update. No gradient calculation or process reward is needed.
Results: ES outperforms RL on key aspects
To evaluate this method, we used the Countdown arithmetic reasoning task, a benchmark that involves multi-step symbolic computation. It’s particularly challenging for RL because of its sparse rewards and long-horizon dependencies – conditions that make action-space exploration unstable.
The ES approach was benchmarked against state-of-the-art RL baselines including PPO and GRPO across a range of model sizes and families, from 0.5 billion to 8 billion parameters. In every case, ES achieved higher accuracy scores and faster convergence. Smaller models, which tend to struggle under RL fine-tuning, showed particularly steady improvements under ES, but the method scaled effectively to larger models as well.
The original search space is 7B parameters; this demo illustrates the search process in 2D.
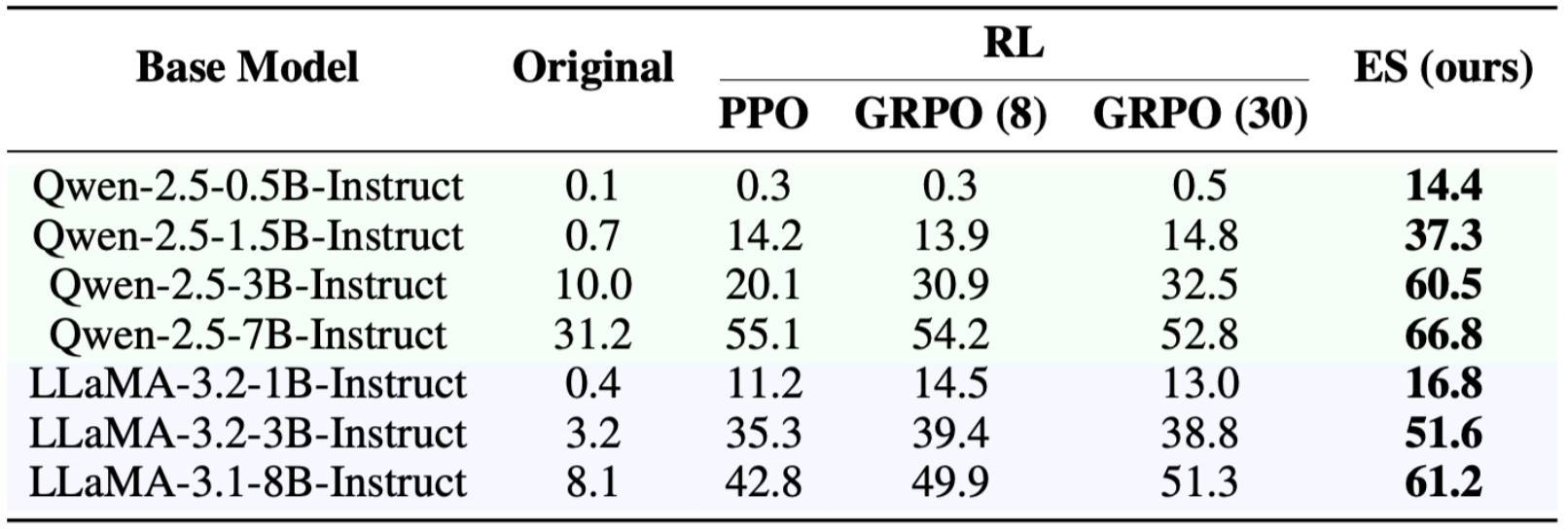
Table 1: Accuracy on the Countdown task across models and fine-tuning methods.
ES consistently outperforms PPO and GRPO across all model sizes — from 0.5B to 8B parameters — with no custom hyperparameter tuning or reward shaping.
A more reliable fine-tuning paradigm
One of the most promising aspects of this approach is its reliability. Evolution strategies demonstrate low variance across random seeds, minimal sensitivity to hyperparameters, and no observable reward hacking. The method does not require gradients or the delicate actor-critic architecture typical of RL, yet consistently discovers high-performing policies with fewer environment interactions.
As models continue to scale, this kind of reliability becomes increasingly valuable. ES reduces sensitivity to initialization and hyperparameter setup, making it easier to apply across diverse use cases without fragile tuning. These properties make it well-suited not only for research but also for robust production deployments.
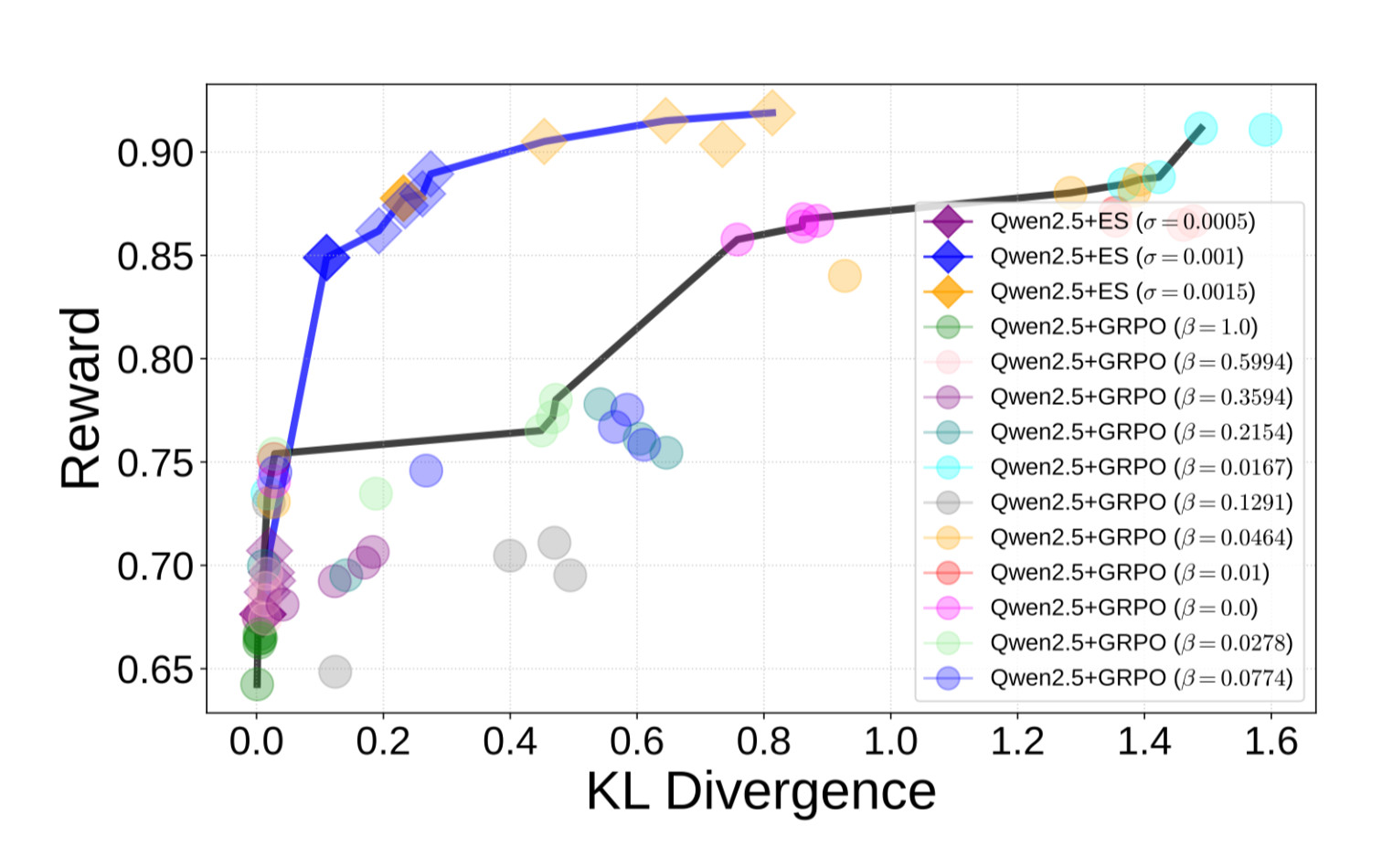
Figure 2: Reward vs. KL divergence during fine-tuning.
KL divergence here measures how much the fine-tuned model behavior deviates from the base model – larger divergence suggests more drastic behavioral shifts, which can lead to instability or unexpected outputs. The ES models (blue) discover better tradeoffs than GRPO (black), achieving higher reward without needing KL penalties. This suggests ES follows a fundamentally different fine-tuning trajectory.
The future: Expanding the fine-tuning toolbox
This work repositions evolution strategies as a practical and scalable alternative to reinforcement learning for fine-tuning large language models. By removing the need for gradient calculations, ES simplifies the training pipeline while delivering strong results across robustness, efficiency, and stability.
Looking ahead, ES could be applied to a wide range of post-training challenges. These include reasoning incentivization, exploration-required tasks, safety alignment, and continual learning – domains where RL has traditionally been the default. As models continue to grow in complexity and importance, having more reliable tools for fine-tuning will be essential.
We are excited about the possibilities this research unlocks. Evolution strategies offer a fundamentally different path forward, and we look forward to exploring how this framework can be extended and applied to new fine-tuning objectives that ultimately lead to next-level intelligence of large models.

Xin is a research scientist that specializes in uncertainty quantification, evolutionary neural architecture search, and metacognition, with a PhD from National University of Singapore