March 4, 2026
Evolution Strategies at Scale: Expanding ES Fine-Tuning to Harder Reasoning Tasks

Evolution Strategies at Scale: Expanding ES Fine-Tuning to Harder Reasoning Tasks
Evolution Strategies (ES) fine-tune billion-parameter models without backpropagation. See how ES performs on math, ARC-AGI, and Sudoku benchmarks.

Key Takeaways
- Evolution Strategies (ES) can fine-tune billion-parameter language models without backpropagation.
- ES performs competitively with PPO- and GRPO-based reinforcement learning (RL) on structured math reasoning benchmarks.
- ES improves model performance on ARC-AGI and Sudoku, extending beyond symbolic reasoning tasks.
- ES demonstrates lower run-to-run variance and reduced hyperparameter sensitivity compared to RL fine-tuning.
- Gradient-free fine-tuning is practical at modern model scales and reduces engineering overhead.
What Are Evolution Strategies (ES)?
Evolution Strategies (ES) are gradient-free optimization methods that update model parameters by directly exploring parameter space, rather than computing gradients through backpropagation.
Unlike reinforcement learning (RL) methods such as PPO or GRPO, ES:
Does not require gradient synchronization across machines
Optimizes directly on outcome-level rewards
Avoids token-level credit assignment
Operates entirely in parameter space
This removes several sources of instability common in RL-based post-training.
From Proof of Scale to Generalization
When we first showed that Evolution Strategies could fine-tune billion-parameter language models without backpropagation, it challenged a long-standing assumption in the field: that gradient-free methods cannot operate effectively in extremely high-dimensional parameter spaces.
Those results demonstrated that ES was not only viable at the billion-parameter scale, but competitive with state-of-the-art reinforcement learning (RL) across stability, robustness, tolerance to long-horizon outcome rewards, and training cost. We validated this across multiple fine-tuning settings, including symbolic reasoning and behavioral objectives that exposed known weaknesses in RL such as reward hacking and instability across runs.
Why Scaling Alone Is Not Sufficient
A method does not become a foundation for post-training because it succeeds in a few controlled settings. It must prove that its strengths persist as tasks diversify, models vary, and problem structure becomes more demanding.
In this expanded version of Evolution Strategies at Scale, we substantially broaden the evaluation. We extend ES across new reasoning domains and more demanding benchmarks to assess whether its core advantages remain intact under greater complexity.
Taken together, these experiments move ES from an initial proof of capability to a broader demonstration of generality, revealing that its advantages in stability, robustness, and gradient-free optimization persist across diverse reasoning domains.
Animation 1: Visual representation of evolution strategies moving within a loss landscape, improving performance on math problems throughout.
From Proof of Scale to Broader Reasoning Performance
To understand whether ES generalizes beyond its initial evaluation settings, we expanded testing across several types of reasoning challenges, including established math benchmarks where RL dominates, abstract reasoning in ARC-AGI, and structured constraint-solving in Sudoku. Each category stresses different aspects of post-training, offering a clearer picture of whether ES functions as a general-purpose optimization framework rather than a task-specific result.
1. Math Reasoning Benchmarks
Reinforcement learning has become the dominant approach for post-training LLMs on math reasoning tasks. To assess whether ES can operate effectively in this setting, we fine-tuned Qwen2.5-Math-7B using ES on the MATH dataset and evaluated across established benchmarks, including:
OlympiadBench
MATH500
Minerva
AIME 2024
AMC
Results
ES significantly improves the base model across all benchmarks tested. When compared against strong RL baselines from the literature, including PPO- and GRPO-based systems trained with mature pipelines, ES achieves competitive performance.
These RL baselines reflect substantial algorithmic refinement and task-specific tuning. In contrast, the ES implementation used here is deliberately streamlined, without additional enhancements such as mirrored sampling or advanced optimizers. Even in this simplified form, ES performs effectively in a domain where RL has become the default.
These results show that ES is not confined to symbolic or behavioral toy tasks. It operates competitively in structured math reasoning benchmarks that require multi-step logic and outcome-only supervision.
Core Claim
ES is competitive with established RL fine-tuning methods on structured, multi-step math reasoning benchmarks.
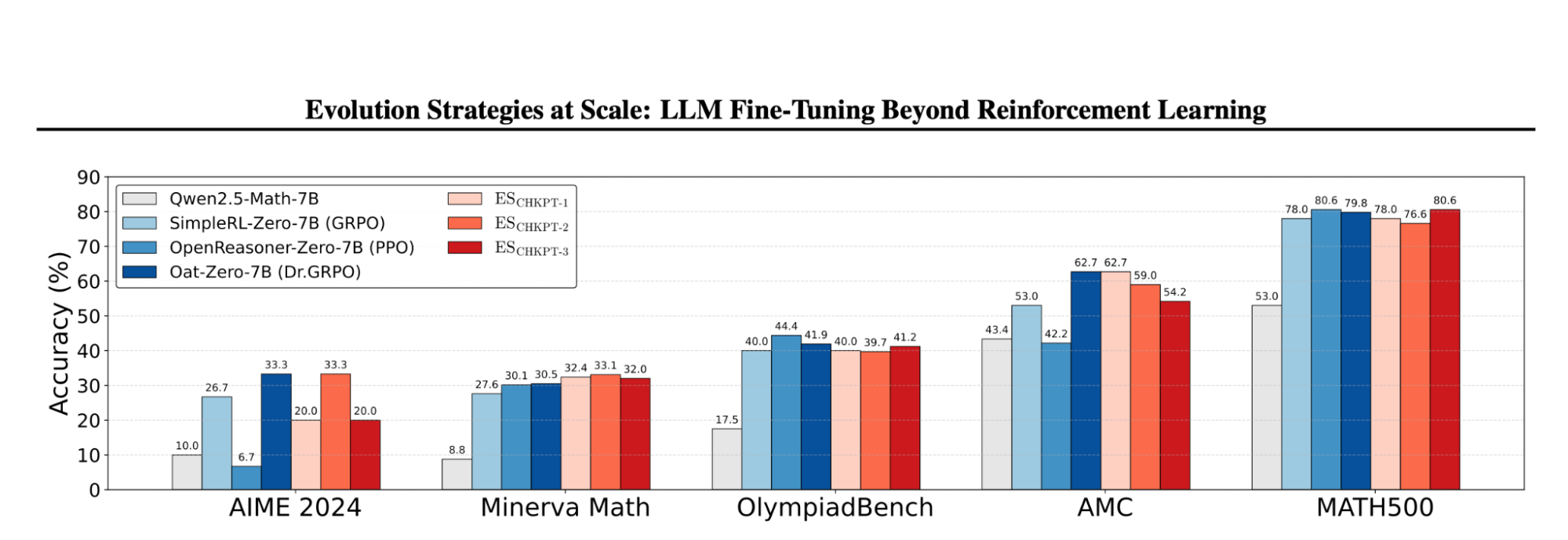
Figure 1: Performance of ES compared to strong, well-established RL baselines across math reasoning benchmarks. Across all benchmarks, ES achieved competitive performance compared to OpenReasoner-Zero-7B (PPO), Simple-RL-Zero (GRPO), Oat-Zero-7B (Dr.GRPO).
2. ARC-AGI: Abstract Pattern Reasoning
ARC-AGI is designed to measure fluid intelligence through abstract pattern recognition and transformation tasks. Unlike traditional NLP benchmarks, ARC-AGI requires models to infer latent rules from minimal examples and apply them consistently.
Result
Base LLMs perform poorly in this setting without targeted adaptation. After ES fine-tuning, performance improves substantially, demonstrating that parameter-space exploration can adapt models to structured reasoning tasks that extend beyond language modeling objectives.
This result is significant because ARC-AGI differs fundamentally from the symbolic reasoning tasks used in the original study. The improvement observed here suggests that ES is not narrowly tuned to a particular reward structure or benchmark format. Instead, it appears capable of driving adaptation in domains that demand abstraction and rule induction.
Core Claim
ES improves performance on abstract reasoning tasks that differ fundamentally from symbolic math benchmarks.
3. Sudoku: Structured Constraint Solving
Sudoku presents a different reasoning challenge. Solutions must satisfy global consistency constraints across an entire grid. Errors propagate across rows, columns, and sub-grids, requiring coherent structured reasoning rather than local token-level correctness.
Result
Base LLMs struggle in this environment without specialized adaptation. After applying ES, performance increases markedly. This demonstrates that ES can improve models on constraint-based reasoning problems where global structure and internal consistency are critical.
Together, the ARC-AGI and Sudoku experiments show that ES extends beyond symbolic benchmarks into tasks that require structured inference, rule consistency, and global reasoning.
Core Claim
ES improves performance on global constraint-based reasoning problems.

Table 1. Accuracy (%) on solving puzzle problems. Original refers to directly evaluating the base model without any fine-tuning. ES fine-tuning improves performance significantly, demonstrating that it can be applied to a range of problems.
Robustness Across Models and Runs
A consistent theme across both the original and expanded experiments is reliability.
In prior evaluations, RL fine-tuning showed sensitivity to hyperparameters, base model selection, and run-to-run variance. Certain configurations required careful tuning of penalty coefficients and learning rates to avoid instability or reward hacking.
Across the expanded ES experiments, performance remains stable across model families and runs using fixed hyperparameters. ES operates directly in parameter space, tolerates long-horizon outcome rewards, and avoids token-level credit assignment. These properties contribute to lower variance and consistent improvements without task-specific adjustments.
As models scale and fine-tuning moves into more complex deployment settings, this kind of stability becomes increasingly important.
ES vs RL Fine-Tuning: A Quick Comparison
| Feature | Evolution Strategies (ES) | PPO / GRPO (RL) |
Requires backpropagation | No | Yes |
Gradient synchronization | No | Yes |
Token-level credit assignment | No | Yes |
Hyperparameter sensitivity | Lower | Higher |
Run-to-run variance | Lower | Higher |
Broader Implications for Post-Training
These expanded experiments show that ES fine-tuning was not limited to a specific task, benchmark, or model configuration.
With minimal configuration changes and without gradient-based optimization, ES remains effective across:
Multiple model families and parameter scales
Established math reasoning benchmarks
Structured puzzle domains
Sparse, long-horizon outcome rewards
The broader implication is not that ES replaces reinforcement learning in every context. It is that full-parameter, gradient-free fine-tuning is practical at modern model scales and competitive across diverse reasoning domains.
Because ES operates without backpropagation, it reduces memory overhead and removes the need for gradient synchronization across machines. Because it optimizes directly on response-level rewards, it enables outcome-driven adaptation without token-level credit assignment. And because it demonstrates stable behavior across runs and model families, it lowers the engineering burden required to make fine-tuning reliable.
Why This Matters
As large language models are increasingly deployed in scientific workflows, engineering systems, and decision-support tools, post-training methods must be scalable, stable, and adaptable across tasks. This work expands the design space of post-training algorithms by showing that parameter-space exploration can meet those demands at scale.
What began as a proof that ES could operate at billion-parameter scale now suggests something more foundational: gradient-free fine-tuning is not a limitation. It is a viable alternative path for how large models can be adapted in practice.

Xin is a research scientist that specializes in uncertainty quantification, evolutionary neural architecture search, and metacognition, with a PhD from National University of Singapore