May 20, 2025
Code versus Model in Multi-Agentic Systems

Code versus Model in Multi-Agentic Systems
Best practices for balancing LLM reasoning and coded logic for more accurate, scalable, and reliable multi‑agent systems in Neuro SAN
In working with clients on building multi-agent systems, I’m often faced with the question of error propagation, especially when multiple agents are involved in an operational flow or when responding to a query or command. LLMs confabulate (i.e., hallucinate) and often miss some details on their instructions or context, or make mistakes in what they generate. LLMs can also be inconsistent in what they generate, and often quite sensitive to minor differences in their input context. How then can we rely on them to augment our businesses and applications?
Of course, these limitations are not restricted to multi-agent systems and apply even more to single agent approaches, where a much larger job description is assumed for the agent, and so some of these problems can be aggravated and more consequential.
In this article, I would like to introduce an approach that can greatly mitigate the risks listed above. Something of a ‘best practices’ for designing and developing multi-agent systems.
A modern AI Agent is comprised of an LLM, and some code. The code allows the LLM to actuate its intentions using the tools we assign to it. Most systems facilitate the calls directly, with no intermediate calls (e.g., calling MCP servers), but some implementations, including our own Neuro AI Multi-Agent Accelerator allow for developers to write code that would run prior to calling tools (i.e., coded tools).
This duality of LLM and code is useful and, as an important step in our design of a multi-agentic system, this allows us to think about what part of an agent’s behavior needs to be handled by the LLM, and which part needs to be coded.
When dealing with an agent, we should always assume some autonomy of behavior. An agent should be allowed, part of the time, to decide on its own which of its tools to use, in what order, and how.
There is a tendency, sometimes, to think of AI agents as we did of software modules and try to control them and make them consistent. This is understandable, but defeats the whole purpose of agentification, which requires ceding some control to agents, and accepting some level of inconsistency, in exchange for robustness, efficiency and quality.
But where do we draw that line? If a module is very sensitive and must be consistent and controlled one hundred percent of the time, then maybe it should not be an agent. On the other hand, if the LLM in an agent makes a minor mistake in its output, and sends that on to another agent to process, we will have the error propagated and amplified, so how do we mitigate that risk. We can, of course, have agents check the work of other agents and reduce the risk of error propagation, which is already better than single-agent systems, but this comes at a cost: more agents mean more tokens, which means costlier processing and slower response time.
Let’s get back to the basics. What are LLMs good at? They can reason, they can generate code or API calls based on intent-based natural language instructions, and they can, in turn, communicate intent robustly, using natural language — a capability that makes multi-agentic systems future-proof, because human language is itself future proof, able to produce new concepts that never existed before.
My suggestion, therefore, is to divide an agent’s responsibilities between those needing an intelligent knowledge-worker-in-a-box and those requiring predefined rules applied consistently. The former can be delegated to the agent’s LLM, and the latter should be programmed into the coded part of the agent. Our secret tool to help us with this division of labor is sly_data: a data structure that can be operated upon by agent tools, and that gets passes around between agents through code, and so is not necessarily subject to LLM processing.
Let me give you an example…
Let’s build a multi-agent system that builds multi-agent systems. I will use the Neuro AI Multi-Agent Accelerator for this.
In the accelerator, agents and tools are defined similarly, both with a set of arguments that define how they should be called. Note that there is flexibility in this protocol in that an agent can define its argument as being a textual description of what is expected of it, so basically, agents can, if needed, communicate in natural language.
A tool call by an agent (which, as I mentioned, is the same if the tool is another agent) is controlled by the LLM in the calling agent. This means that whether or not the call is to be made, in what order, and what value the args should take, are all determined through the reasoning of the LLM, which, of course, is informed by its pretraining, any finetuning it may have gone through, and, more importantly, its system prompt and input context. We should recognize, therefore, that this part of the Agent is subject to all the LLM limitations noted above.
If we were to create an agents-creating-agents system solely using this inter-agentic protocol, we would be relying entirely on the LLMs. This is fine for simpler tasks, but, as you will see, it can be problematic, even with the most powerful of LLMs, for more complex definitions requiring rigid syntax.
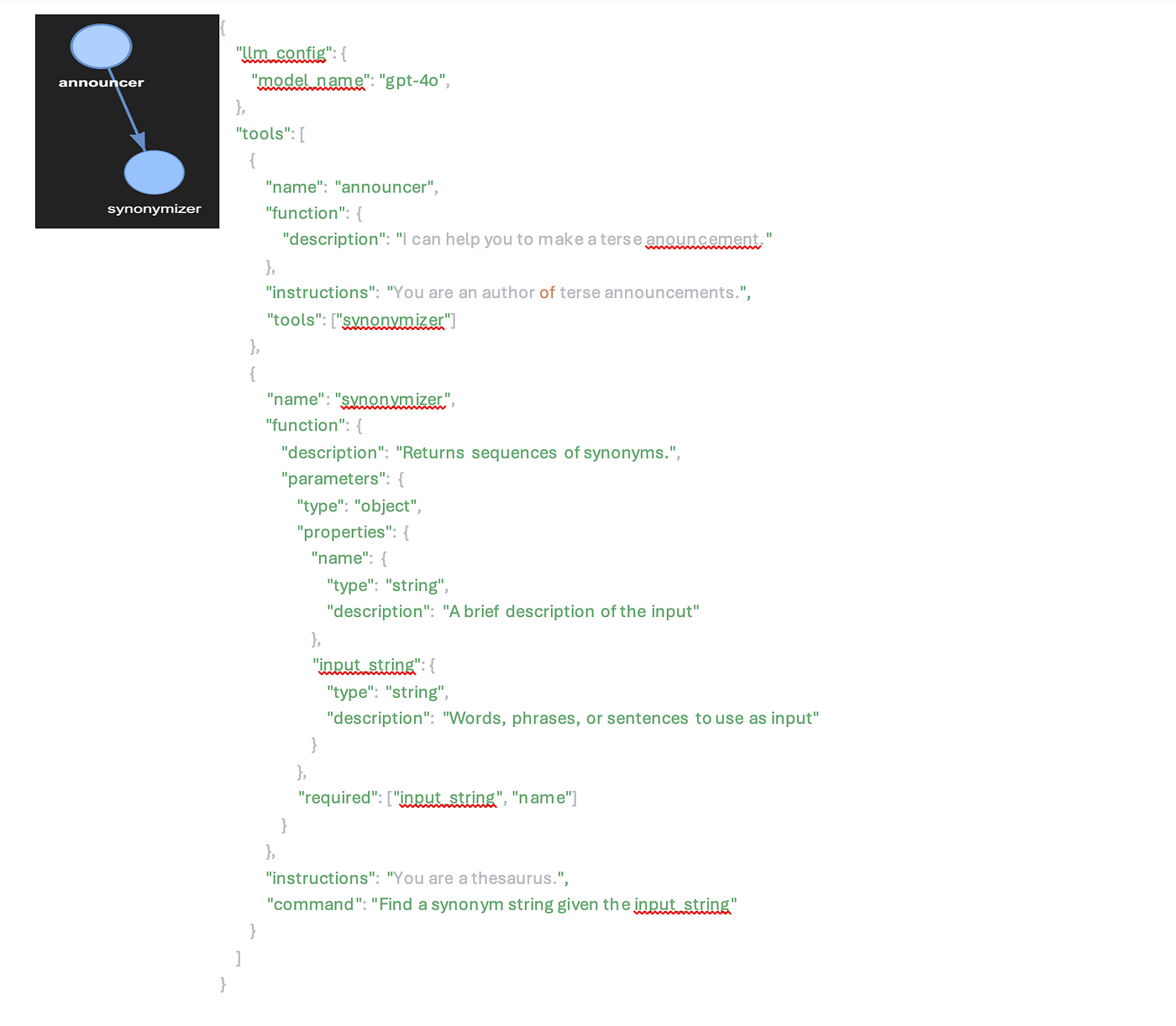
Figure 1. Example simple agent network definition hocon.
In the multi-agent accelerator, a network of agents is defined in hocon format, which is a config file standard. A simple agent network with two agents will have to define the top agent and its single down-chain in a format like the example in figure 1.
Our agents-creating-agents system will have to design an agent network and produce it adhering to this strict format, so that it can be readily served by the Multi-Agent Accelerator. The problem here is, by relying on the LLMs in the agents to construct the agent network definition in this strict unforgiving syntax, we are asking the LLMs to do what they are not that good at doing. Complying to a rule-based syntactic format is better achieved in code. First, let me show you the problem, and then I will give you the fix, which, as you might have guessed, has to do with the division of labor noted above.
In our multi-agent system to design multi-agent systems, we will need to come up with the roles and connections of the agents, the tools they may need to use, each agent’s job description in the form of a system prompt, and some sample queries the end system should be able to handle. This, however, is insufficient, as the LLMs will inevitably make mistakes in constructing the agent network, and so we will need to have agents checking the work of the other agents and validating them before the final agent network definition is returned.
Figure 2 shows one possible design for a multi-agentic system for designing multi-agentic systems.
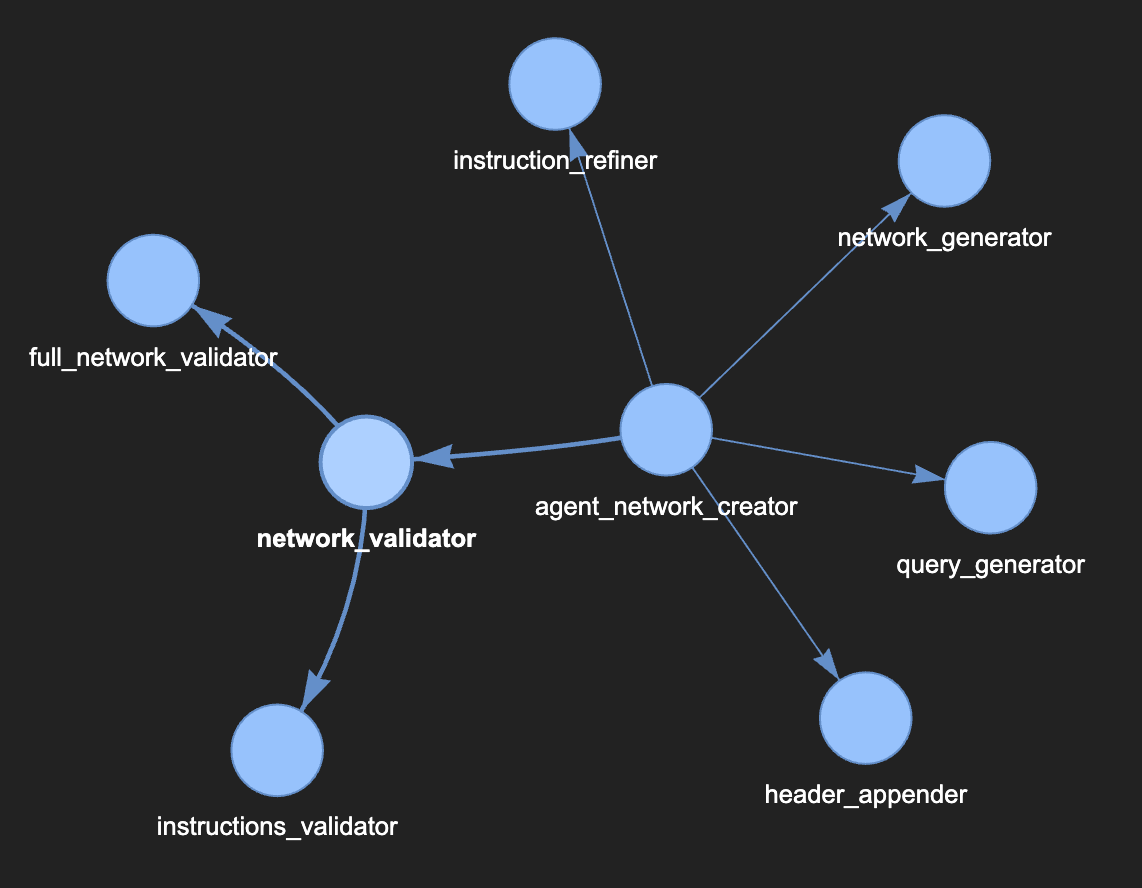
Figure 2. A multi-agentic system for building multi-agentic systems, relying exclusively on LLM-based communications. The arrows between the agents denote the inter-agent communications and the hierarchical relationship.
In this image, the agent_network_creator agent will take a description of the organization or process for which we need to create an agent network, it then asks the network_generator to design the network. The network_generator generates a hocon formatted design for the network and returns it and the query_generator returns some sample queries and commands the generated agent network should be able to handle. The agent_network_creator then iterates through the agents in the network and asks the instruction_refiner to generate comprehensive system prompts for every agent. The header for the hocon file is then appended using the header_appender agent, and the resulting definition is sent to the network_validator agent, which first iterates through the individual agents, validating them using the instructions_validator, and then calls the full_network_validator to check the entire design. The agent_network_validator will iterate against the network_validator and works with its downchain agents to resolve any issues reported by the validator, before returning the full definition back to the user.
Note that the prompt for the network_generator, header_appender, instruction_refiner, instructions_validator, and full_network_validator agents all need to have one-shot examples of the syntax for multi-agent definitions in order to be able to generate or validate them. Figure 3 is a snippet of the full_network_validator system prompt, illustrating the complexity of the task we are assigning to this agent.

Figure 3. A snippet of the full_network_validator’s system prompt.
It should be clear that the agents in this design are often tasked with jobs that are better performed by code, and by relying entirely on LLM reasoning, we have made our system prone to inconsistencies and errors in its production of agent definitions. In our implementation, using GPT-4o as the LLM for all agents, they still often miss out on one or two details in their prompts, or make mistakes in syntax on the definition. The power of GPT-4o means that sometimes the system does get everything right, and when it misses something, fixing it manually is still more efficient than designing the entire network from scratch. Even so, there must be a way to do better. And there is.
In the Multi-Agent Accelerator, LLM-based agent or tool calls are not the only communication between agents. Every time an agent calls a tool, or another agent, a data structure called sly_data is also passed along between the agents. This communication is not in the control of the LLMs, and it is used, for example, to pass encrypted authorization tokens between agents so that access controls are respected by any tools within the multi-agentic system. The sly_data can also be used to pass around data structures that the agents can manipulate through a combination of LLM reasoning and/or coded tools (see figure 4.)

Figure 4. Inter-agent communications in Neuro AI Multi-Agent Accelerator. The called Agent then returns both the agent’s LLM generated results, as well as the Sly_data, which may have been processed by the called agent’s tools (not shown).
We can therefore design a new agent network for designing agent networks, this time, assigning the creative tasks to the LLM, and leaving the formatting to the code.
Figure 5 shows our new and improved design.
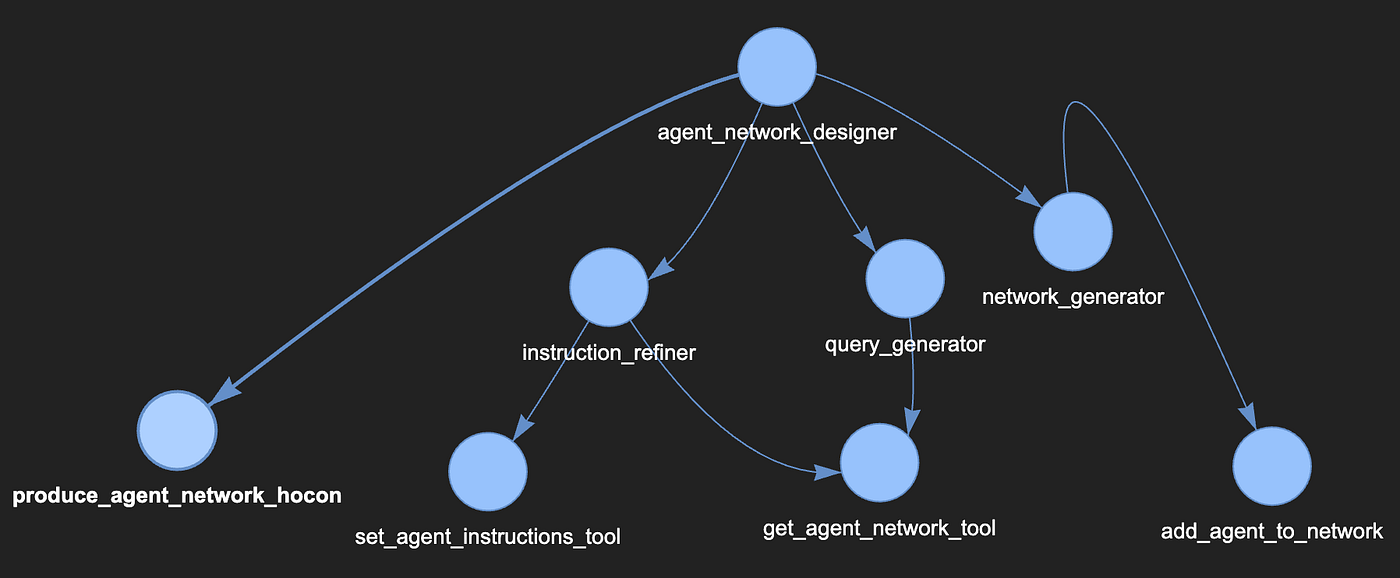
Figure 5. A new design for the agent network designer agent network.
In this new design, the leaf nodes are all tools that manipulate a data structure within the sly_data containing the agent network definition being produced. The network_generator, for example, calls the add_agent_to_network tool repeatedly, adding agents to the agent network definition contained in the sly_data. Every time the query_generator, or instruction_refiner agents need to make a decision regarding the agent network, they can use the get_agent_network_tool to retrieve it from the sly_data, which means, we no longer need to count on the LLMs within the agents to reconstruct the hocon design, propagating possible errors in the definition syntax. As a final call, the agent_network_designer agent calls the produce_agent_network_hocon tool to map the completed design it retrieves from the sly_data into a definition hocon, append the header, and even save it as a file directly into the agent registry (see figure 6).
Note that the sly_data being manipulated is being passed between the agents (see figure 7) and not in a centralized place like figure 6 implies. This means that agent encapsulation and distribute-ability is respected.
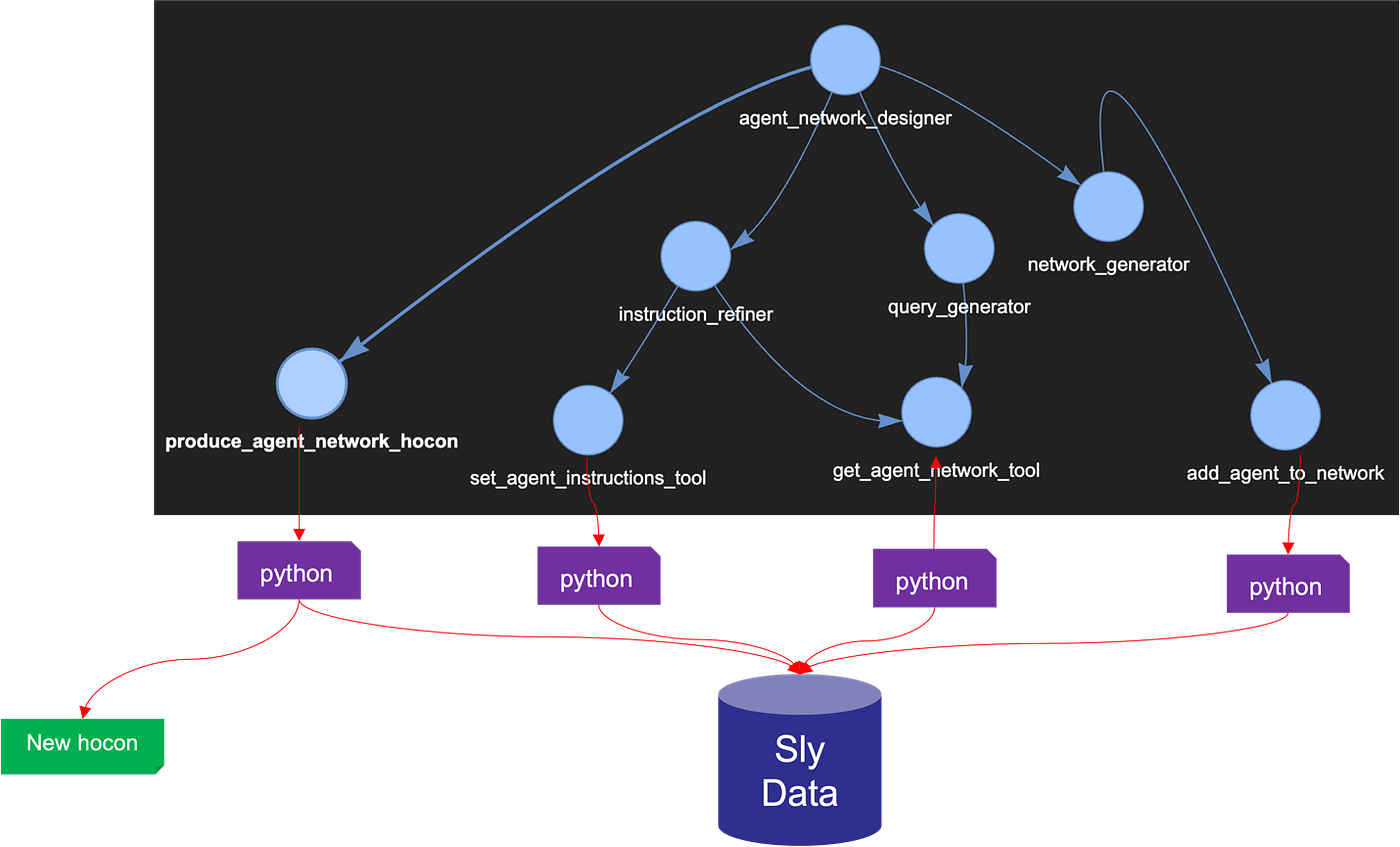
Figure 6. A better division of labor between LLM and coded tools. The red arrows denote API calls from within the agents’ coded tools (in Python), modifying or reading the data structures within the sly_data.
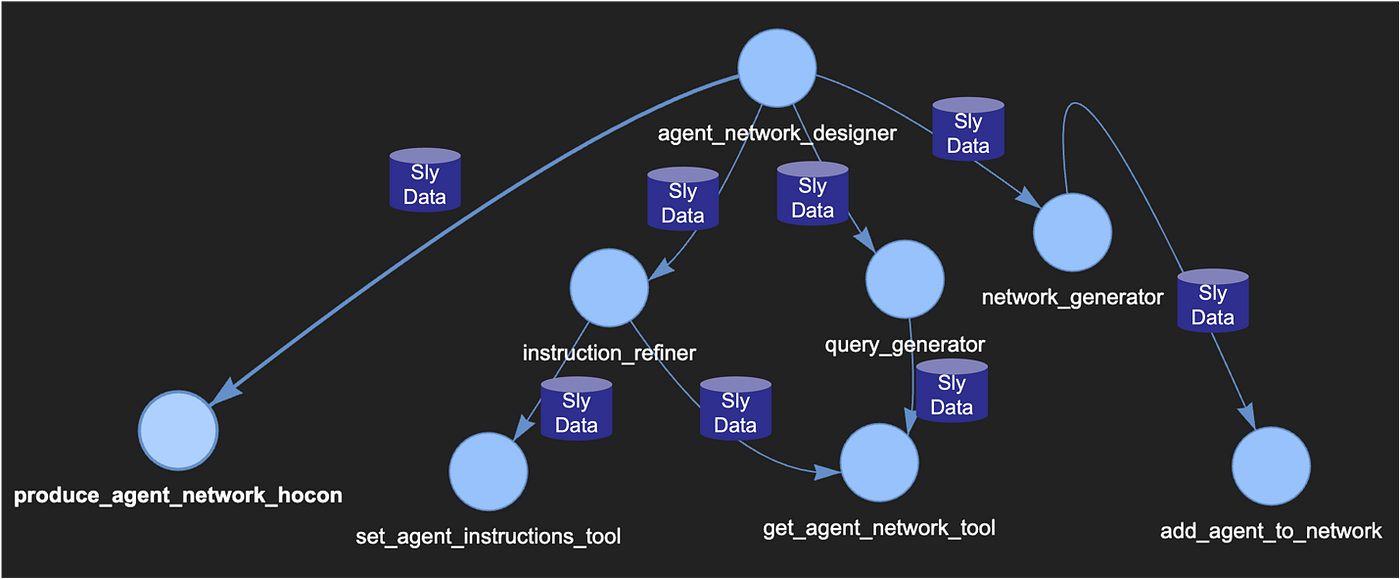
Figure 7. Sly data is not centralized but being passed between the agents through code, with no need for LLM processing.
This is a much cleaner and more scalable design, removing the necessity for the validator agents, because syntax is all handled in code (which can be validated through unit tests). It is therefore faster and less costly too, because we are using much smaller prompts, and the agents don’t need to send a ton of definition hocons back and forth. Most importantly, the system is able to create larger agent networks, and the LLMs are much more reliable, as they are only tasked with reasoning and creativity.
Feel free to download and use the accelerator. We have both examples above available in the demos repo.
In summary, when creating multi-agent systems, we should be mindful of the division of labor between the LLM and coded parts of agents, and make sure we use platforms, like the Neuro AI Multi-Agent Accelerator, which are designed to best support such implementations.

Babak Hodjat is the Chief AI Officer at Cognizant and former co-founder & CEO of Sentient. He is responsible for the technology behind the world’s largest distributed AI system.