March 25, 2026
Blessing of Dimensionality in LLM Fine-tuning: A Variance–Curvature Perspective

Blessing of Dimensionality in LLM Fine-tuning: A Variance–Curvature Perspective
Recent research showing that larger models exhibit lower effective curvature dimension, making them easier to optimize.
Key Takeaways
Fine-tuning is effectively low-dimensional and only a few directions actually matter, which makes large models easier to optimize than expected.
Small populations (~30–40 samples) are enough and showcases that simple methods like ES can match more complex RL approaches.
Training follows a rise–then–decay pattern. This matters because performance drops are natural, not necessarily a failure.
Optimization is not a needle-in-a-haystack problem and many directions work, enabling simpler and more scalable fine-tuning.
Figure 1: Toy example of evolution strategies transitioning from signal dominant to variance dominant regime under different population sizes
As large language models scale, a basic assumption has guided much of machine learning: more parameters should make optimization harder. Larger systems introduce more dimensions, more noise, and a combinatorial explosion of possible updates.
Yet recent results in LLM fine-tuning are beginning to challenge that view. Methods based on simple random perturbations in parameter space which have long been considered impractical at scale are successfully improving billion-parameter models with surprisingly small populations. At the same time, fine-tuning runs across multiple methods exhibit a consistent pattern: reward improves rapidly, peaks, and then declines, even when training conditions remain fixed.
Together, these observations point to a gap in our understanding of how large models are actually optimized in practice.
In our recent paper, The Blessing of Dimensionality in LLM Fine-tuning, researchers from Cognizant AI Lab and MIT offer a new perspective. The key idea is that fine-tuning does not depend on navigating the entire parameter space. Instead, progress is driven by a much smaller set of important directions shaped by the geometry of the optimization landscape.
This view explains both why simple, small-population methods like evolution strategies can work effectively at scale, and why training often improves rapidly before eventually degrading under fixed conditions. The implication is straightforward: what matters is not the size of the model, but the structure of the landscape it is optimized in. In that sense, high dimensionality is not a burden—it can actually make improvement more accessible.
What is the Blessing Of Dimensionality?
The central idea is that fine-tuning does not actually depend on navigating the full, high-dimensional parameter space but is rather governed by a much smaller set of directions called curvature-active directions, specific paths where the reward landscape has a clear slope or where changes meaningfully affect performance. The vast majority of directions, by contrast, are effectively flat and contribute little to learning.
This means that fine-tuning behaves as if it is low-dimensional. So even if the model has billions of parameters, only a small subset of directions matters. As a result, many different parameter updates can lead to similar improvements, as long as they align with this underlying structure.
Optimization does not necessarily get harder as models grow, because the number of important directions does not grow with parameter count. That helps explain why simple methods like small-population evolution strategies can work well at scale—and why high dimensionality can actually make improvement easier to find, rather than harder.
How It Works
Fine-tuning can be understood as an interaction between signal (structure) and noise (stochasticity). Early in the training process, learning is driven by high-curvature directions which provide strong signals, so improvement is fast and consistent. However, as training progresses, these directions become saturated and once this happens, the remaining updates are increasingly dominated by stochastic noise, especially in flatter parts of the landscape.
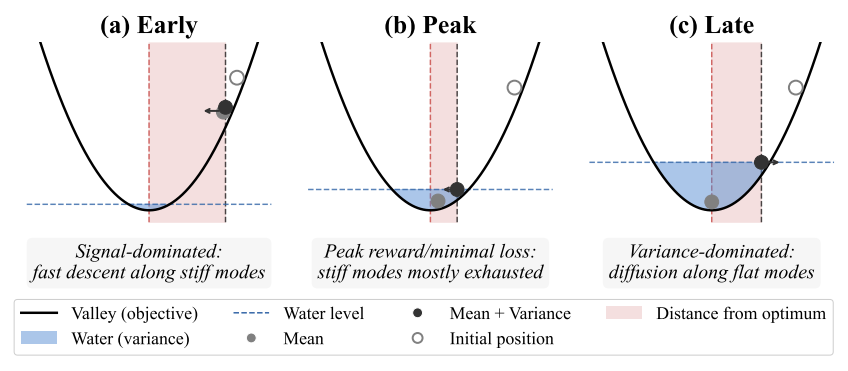
Figure 2. Water-filling schematic for rise–then–decay dynamics. (a) Early: fast improvement along stiff directions while variance is small. (b) Peak: stiff directions are mostly exhausted; variance has risen enough to limit gains. (c) Late: variance-dominated drift along weakly constrained directions yields degradation under fixed stochasticity
This results in a predictable pattern: rapid improvement at the beginning, followed by a peak, and then gradual degradation. This “rise–then–decay” behavior appears across both evolution strategies and policy-gradient methods, suggesting that it is not tied to a specific algorithm, but rather to the structure of the landscape itself.
In such a high-dimensional space, random perturbations should almost never align with useful directions. Intuitively, this would imply that methods like evolution strategies need very large populations to make progress.
However, since improvement lies in a low-dimensional subspace, many random perturbations share similar components along those important directions. In other words, there are many ways to move in a useful direction. The paper refers to this as degeneracy, the idea that improvement is not tied to a single precise update, but to a set of equivalent ones.
This is why small populations are sufficient. Even with limited samples, it is likely that at least one perturbation will align well enough with the curvature-active subspace to produce improvement.
Evolution Strategies as a Probe
The paper uses evolution strategies not just as an optimization method, but as a diagnostic tool to study the structure of the fine-tuning landscape on models ranging from 0.5B to 7B parameters (including Llama and Qwen variants).
ES works by sampling random perturbations, evaluating their rewards, and combining them into an update. Because it relies only on reward evaluations (and not gradients), it can directly probe how different directions affect performance.
In essence, ES can be interpreted as optimizing a Gaussian-smoothed version of the objective. This smoothing filters out small irregularities while preserving the large-scale geometry of the landscape, making it easier to observe how curvature and noise interact.
The Results
The paper evaluates these ideas across multiple tasks—GSM8K, ARC-C, and WinoGrande—using models ranging from 0.5B to 7B parameters. The goal is to test a key hypothesis: if fine-tuning is governed by a low-dimensional curvature structure, then reward-improving updates should remain accessible even as model size grows.
That’s exactly what the results show. Performance improves quickly as population size increases, but only up to a point. Beyond roughly 30 to 40 samples, the gains begin to saturate—and importantly, this saturation point does not shift with model size. Larger models do not require larger populations to find useful updates. In other words, the expected curse of dimensionality does not appear in practice.
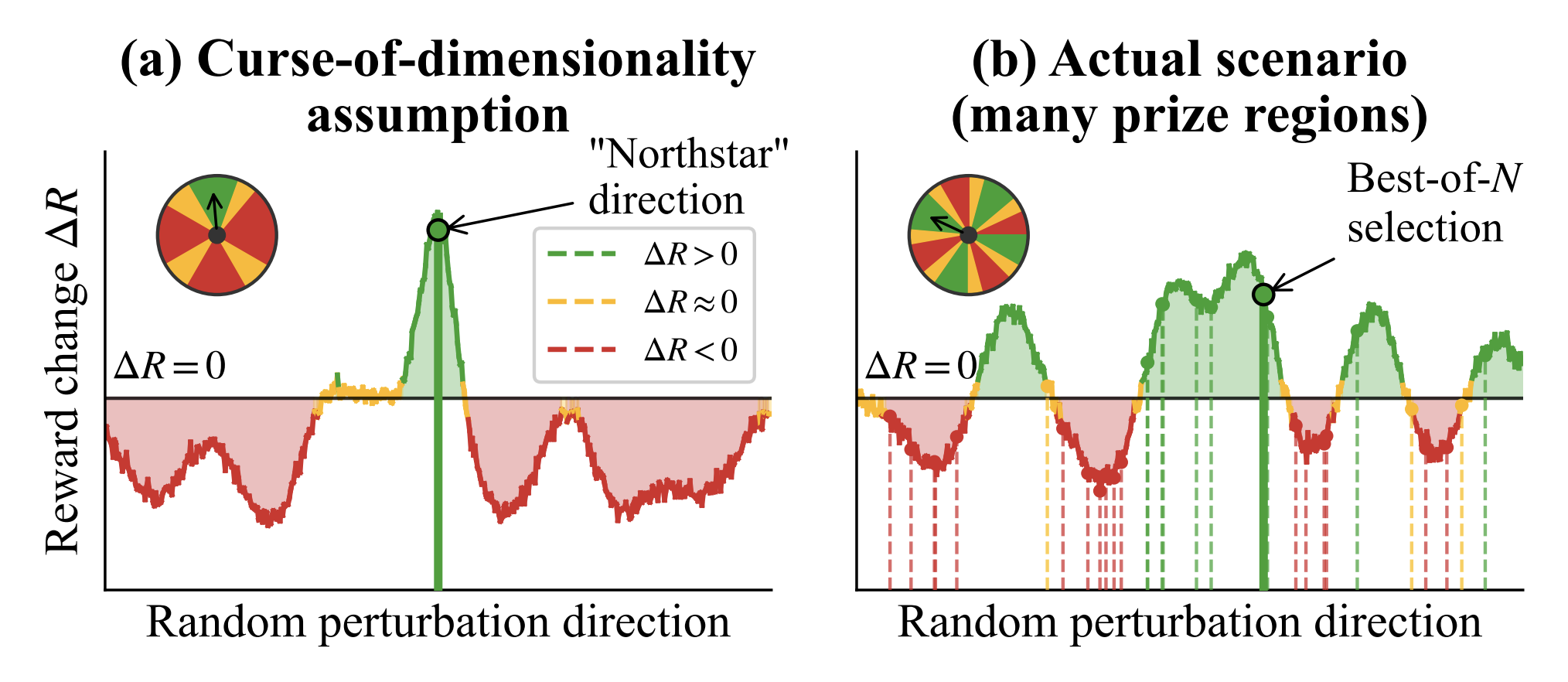
Figure 3. Needle-in-a-haystack versus degenerate “wheel of fortune.” (a) In high dimensions, improvement lies in one rare direction, so random search almost always fails. (b) If improvement depends on a small key subspace, many directions can still help, so picking the best of a few samples works.
This directly challenges classical intuition. Traditionally, optimization is viewed as a needle-in-a-haystack problem, where only one rare direction leads to improvement. If that were true, the number of samples needed to find a good update should grow with the number of parameters. However, empirically, it doesn’t.
Instead, the evidence points to a very different picture. Fine-tuning behaves more like a many-prize landscape. While improvement is governed by a low-dimensional set of important directions, there are many different updates that can still move the model in the right way. Rather than searching for a single perfect direction, optimization succeeds by sampling until it finds one of many good ones.
This is what the paper refers to as degeneracy. Improvement is not tied to a single precise update, but to a set of directions that share similar components along the curvature-active subspace. As a result, many random perturbations have a meaningful chance of producing positive reward changes.
Why It Matters
This work challenges a core assumption in machine learning: that larger models are inherently harder to optimize. Instead, it suggests that fine-tuning performance may depend less on the total number of parameters and more on the underlying structure of the optimization landscape.
That shift has practical implications. If improvement is concentrated in a small set of directions, then effective fine-tuning may not require increasingly complex or resource-intensive methods. Simpler approaches like perturbation-based or population-based strategies may remain viable even as models scale.
It also reframes a common training behavior. The rise–then–decay pattern observed across fine-tuning methods is often treated as instability or failure. This research suggests it may instead reflect a predictable transition from signal-dominated learning to variance-dominated dynamics. That opens the door to more principled strategies around early stopping, noise scheduling, and training stability.
More broadly, the findings point toward a different way of thinking about large models. Rather than viewing scale purely as a source of complexity, this work highlights how structure within high-dimensional systems can make optimization more accessible. Understanding that structure may be key to building more efficient, reliable, and adaptable AI systems

Xin is a research scientist that specializes in uncertainty quantification, evolutionary neural architecture search, and metacognition, with a PhD from National University of Singapore