March 18, 2026
Quantized Evolution Strategies: Fine-Tuning Quantized LLMs at Inference-Level Memory

Quantized Evolution Strategies: Fine-Tuning Quantized LLMs at Inference-Level Memory
Our Lab’s new approach makes it possible to fine-tune quantized language models directly in low-precision space, dramatically reducing the cost of adapting large models.
Key Takeaways
Quantized Evolution Strategies (QES) enable fine-tuning quantized large language models directly in low-precision space.
The method works without backpropagation, using a zeroth-order optimization approach.
QES allows models to be fine-tuned at roughly the same memory cost as inference.
The method introduces two innovations: accumulated error feedback and stateless seed replay.
Experiments show major improvements in reasoning accuracy on quantized Qwen2.5 models.
Quantization has become one of the most important techniques for deploying large language models efficiently. By compressing model weights into low-precision formats such as INT8 or INT4, quantization dramatically reduces memory usage and inference cost. Models that would otherwise require specialized infrastructure can often run on consumer GPUs or other constrained hardware with little loss in capability.
But quantization introduces a fundamental limitation.
Once a model is quantized, it becomes extremely difficult to improve. Most modern training methods rely on backpropagation and high-precision gradients, which assume parameters exist in a continuous space. Quantized models instead operate in a discrete integer parameter space, where small learning signals vanish when forced onto the quantization grid.
The result is a practical bottleneck. Quantization makes models cheap and accessible to run, but it often turns them into static artifacts that cannot easily be adapted after deployment.
In our new paper, Quantized Evolution Strategies, researchers from Cognizant AI Lab introduce a novel method for overcoming this limitation. Using a backpropagation-free optimization process, our approach enables full-parameter fine-tuning directly in quantized space while preserving the memory efficiency of quantized inference. This is the first approach that makes such fine-tuning practical for large language models in quantized parameter space.
The key result is simple but powerful: if a system can run inference on a quantized model, it can also fine-tune that model.
Why Quantized Models Are Hard to Train
1. Discrete Parameter Space
Training methods for neural networks are built around the idea of continuous parameters. During optimization, the model receives many small updates that gradually move it toward better performance.
Quantized models operate under a very different constraint. Their parameters are restricted to a discrete grid of integer values. Instead of smoothly adjusting weights, the optimizer can only move between fixed steps on that grid.
This creates two fundamental problems.
2. Stagnation From Small Updates
During fine-tuning, many useful updates are extremely small. In continuous space, these updates accumulate over time. In quantized space, however, an update smaller than the rounding threshold (usually equals to half of the grid spacing) simply rounds to zero, leaving the parameter unchanged.
3. Discretization Error
When updates are forced onto a coarse grid, they may deviate from the intended optimization direction. Over many iterations, these distortions accumulate and slow learning.
These effects make quantized optimization far more fragile than standard training.
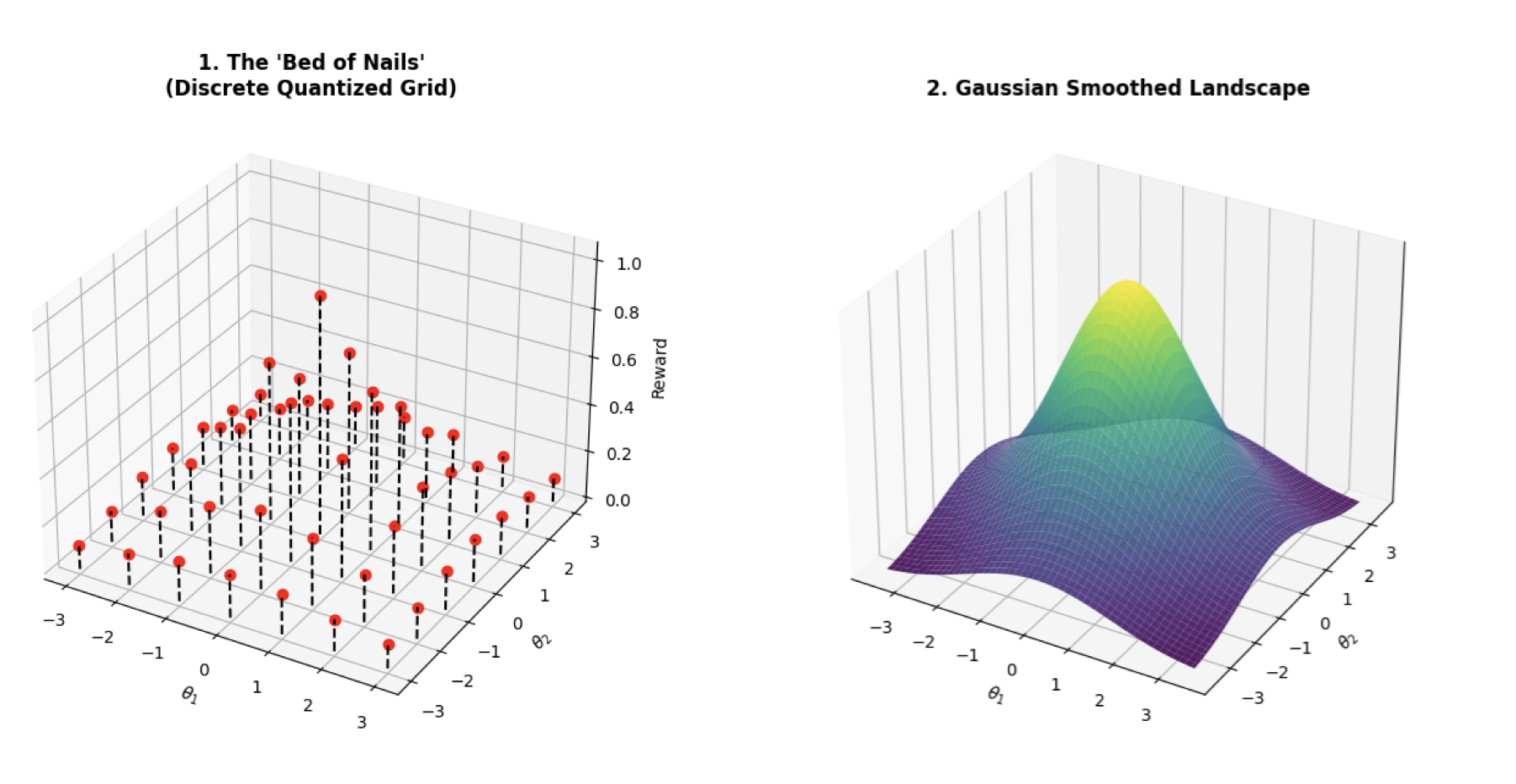
Figure 1. Continuous reward function and its discretized counterpart on a quantized parameter grid. While a continuous objective can be optimized with gradient ascent, optimization on a discrete grid must navigate quantization steps without losing the underlying learning signal.
Introducing Quantized Evolution Strategies
To address these challenges, the paper introduces Quantized Evolution Strategies (QES), an optimization framework designed specifically for quantized models.
What Is Quantized Evolution Strategies?
Quantized Evolution Strategies (QES) is a training method that allows large language models to be fine-tuned directly in quantized parameter space, without converting weights back to high precision or using backpropagation.
Instead of gradient updates, QES uses evolution strategies, evaluating small perturbations of the model and estimating a useful update direction from their performance.
Two mechanisms make this possible:
Accumulated error feedback, which preserves fractional update signals that would otherwise be lost during discretization
Stateless seed replay, which reconstructs optimization trajectories to restore discretization errors with minimal memory usages
Together, these techniques enable full-parameter fine-tuning with memory requirements close to inference-level hardware.
How QES Works
Like traditional Evolution Strategies, QES explores parameter space by generating perturbations of the model, evaluating their performance, and estimating a useful update direction from those results. Because this process does not rely on gradients, it can operate in non-differentiable settings such as quantized parameter spaces.
However, applying standard Evolution Strategies directly to quantized models is not sufficient. The discrete parameter grid causes useful update signals to disappear before they can influence the model.
QES solves this with two key innovations.
The first is accumulated error feedback. Instead of discarding the fractional portion of each update that fails to change a quantized weight, QES preserves that residual signal and carries it forward to future iterations. Over time, these small residuals accumulate until they become large enough to trigger a discrete parameter update.
This mechanism allows the optimizer to maintain high-precision learning dynamics even though the underlying parameters remain quantized.
The second innovation is stateless seed replay. Accumulated residuals normally require storing large high-precision tensors, which would negate the memory advantages of quantization. QES avoids this by reconstructing the accumulated error state using stored random seeds and scalar rewards. The resulting memory footprint is dramatically smaller and negligible.
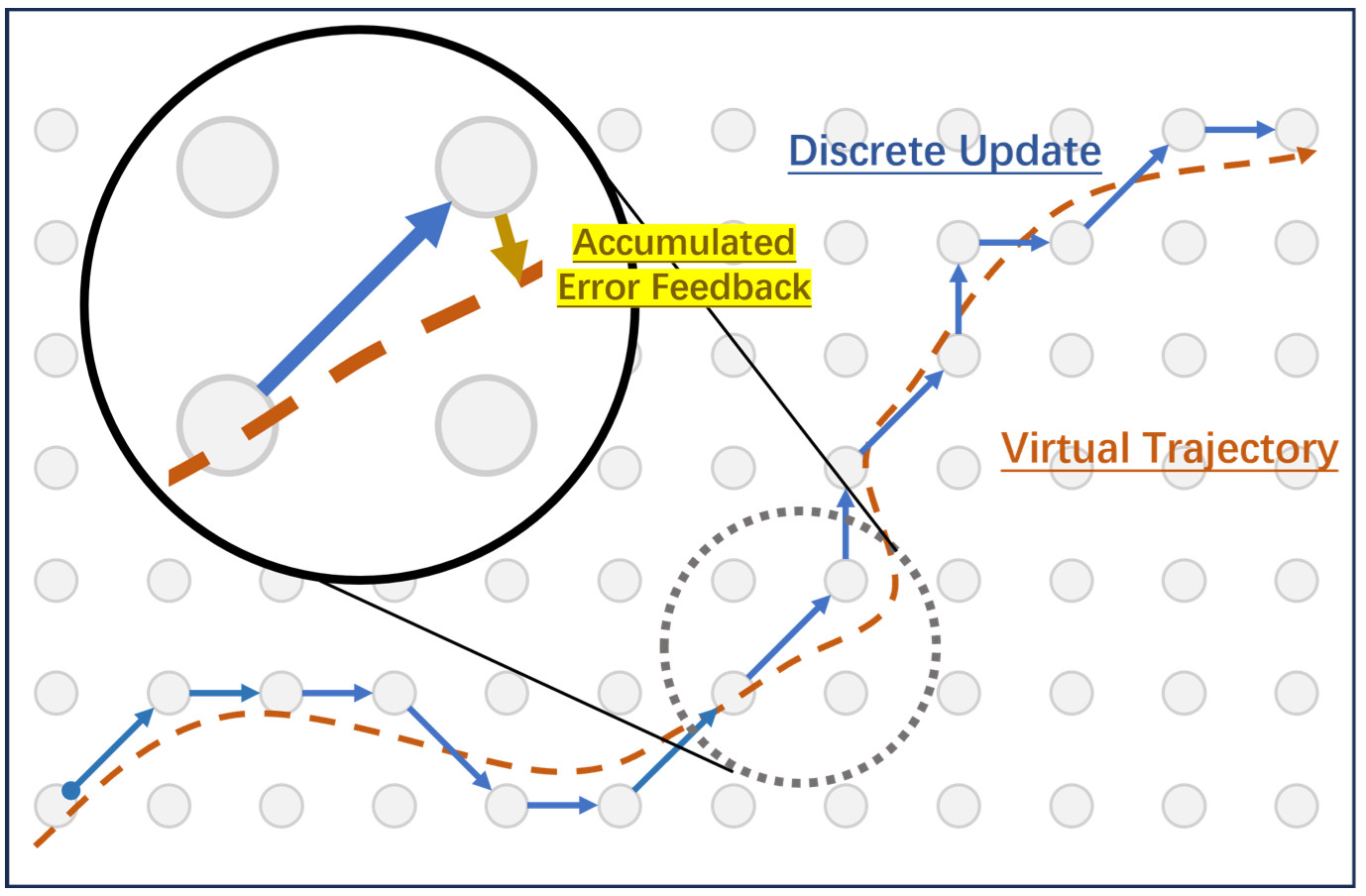
Figure 2. Overview of Quantized Evolution Strategies (QES). The method optimizes quantized language models directly in discrete parameter space. Error residuals accumulate across iterations until they trigger a discrete weight update, preserving high-precision learning dynamics while keeping memory usage close to that of quantized inference.
Fine-tuning at the Cost of Inference
One of the most significant outcomes of QES is that it reduces the memory requirements of training to roughly the level required for inference.
This addresses a major gap in the current AI ecosystem. Quantization has made it possible to run powerful models on modest hardware, but adapting those models has typically required training-scale infrastructure and large optimizer states.
QES changes that dynamic. Because it operates entirely in quantized space and avoids backpropagation, it requires only low-precision model weights and a lightweight optimization history with negligible size.
In practical terms, this means that if a machine can run inference on a quantized model, it can also fine-tune that model using QES.
This significantly expands the environments where model adaptation becomes feasible, enabling customization and post-training improvements on hardware that previously supported only static deployment.
Experimental Results
The paper evaluates QES on Countdown, an arithmetic reasoning benchmark where the model must construct a mathematical expression that reaches a target number using a given set of inputs.
This task provides a compact but demanding test of reasoning ability.
Experiments were conducted using quantized versions of Qwen2.5 models in several formats, including INT4, INT8, and W8A8. QES was compared with both the original quantized models and QuZO, the current state-of-the-art zeroth-order fine-tuning method for quantized models.
The results show consistent and substantial improvements.
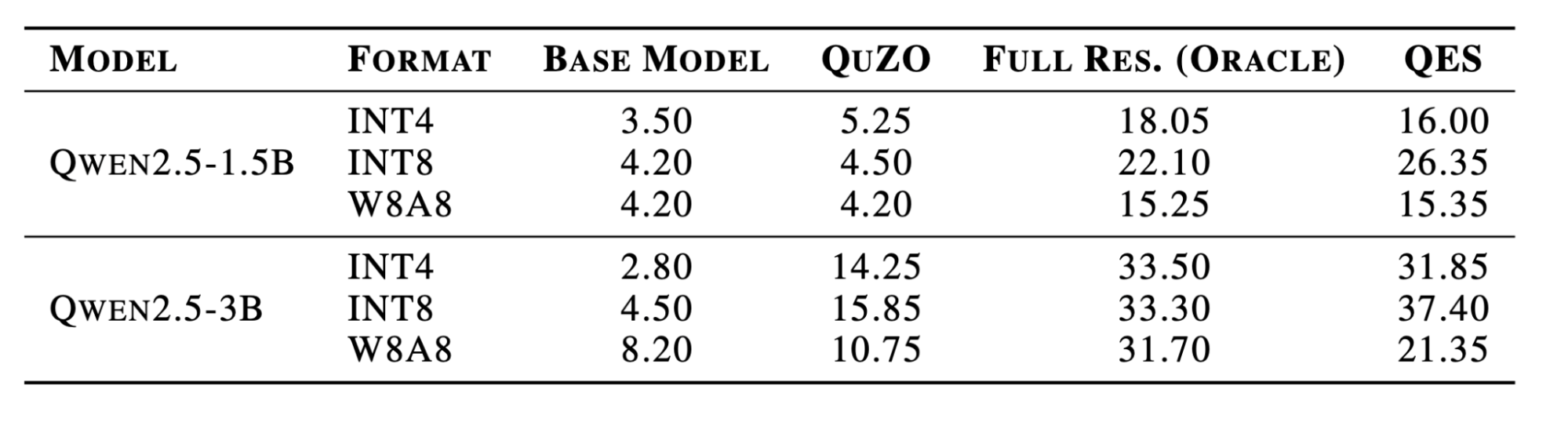
Table 1. Countdown task accuracy across model sizes and quantization formats. QES significantly improves arithmetic reasoning performance compared with both the base quantized models and the prior state-of-the-art quantized fine-tuning method. The method approaches the performance of a full-residual oracle while using far less memory.
Across both model sizes and quantization levels, QES improves reasoning accuracy by large margins. In the most constrained setting, the INT4 version of Qwen2.5-1.5B improves from 3.50 percent accuracy to 16.00 percent after QES fine-tuning. On the larger 3B model, performance reaches over 31 percent.
Training curves further illustrate the difference between QES and existing approaches.
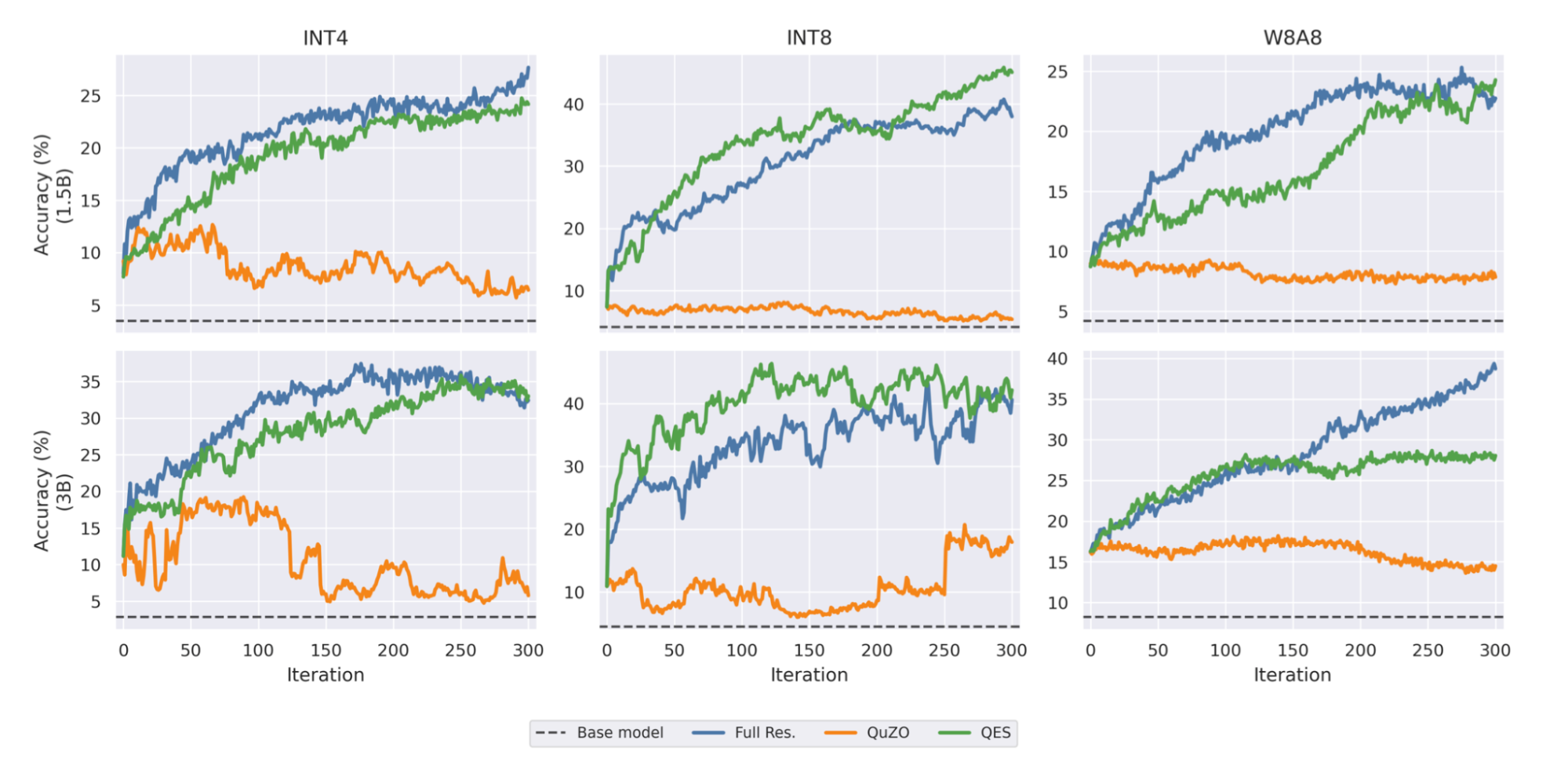
Figure 3. Training curves for QuZO and QES compared with the base model. QuZO struggles to escape early performance plateaus, particularly in low-bit settings, while QES progresses steadily and closely tracks the performance of a full-residual oracle despite using far less memory.
These results demonstrate that accumulated error feedback successfully preserves learning signals that would otherwise disappear in quantized parameter space.
Why This Matters
Quantization has already transformed the way large language models are deployed. By reducing memory requirements and inference cost, it has made powerful models accessible on far more hardware.
However, those models have largely remained static after deployment.
Quantized Evolution Strategies change that by enabling full-parameter fine-tuning directly within quantized models while keeping memory usage close to inference levels. This makes it possible to adapt large models on hardware that previously supported only running them.
Beyond immediate deployment benefits, the approach also suggests a new path for scaling language models. If models can be trained directly in quantized space, the same hardware budget could support far larger parameter counts.
Combining the memory efficiency of quantization with the flexibility of backpropagation-free optimization opens the possibility of scaling and adapting models in ways that were previously impractical.
Quantized Evolution Strategies demonstrate that quantized models do not have to remain static. With the right optimization methods, they can continue to learn and improve while retaining the efficiency that made them deployable in the first place.

Xin is a research scientist that specializes in uncertainty quantification, evolutionary neural architecture search, and metacognition, with a PhD from National University of Singapore