April 30, 2026
How to Make Agent Networks Reliable: A Practical Guide

How to Make Agent Networks Reliable: A Practical Guide
To make agent networks reliable, teams need structured knowledge inputs, precise agent definitions, strong prompt constraints, consistent tool usage, and a test framework that measures correctness across repeated runs.
Agentic systems are easy to build and hard to trust. With tools like neuro-san, a multi-agent network can be created from a prompt in minutes. But a working system is not the same as a reliable one. In production, there is often a gap between what the agent is designed to do and what it actually does across repeated runs.
This gap comes from how these systems behave. Large language models are non-deterministic. The same query can trigger different routing decisions, different tool usage, and different outputs each time. In a multi-agent setup, that variability compounds. A routing agent might call the wrong specialist. A downstream agent might skip a tool and answer from pre-trained knowledge. A response can look correct while missing key constraints or conditions.
These are common failure modes, and many are difficult to detect through manual testing.
A single successful run does not mean the system is correct. It only shows that the system can produce the correct answer, not that it will do so consistently. Without repeated evaluation, teams rely on spot checks and intuition, making it difficult to assess whether changes improve performance or introduce regressions.
To address this, we built a test framework for neuro-san focused on how agent networks behave in practice.
The framework evaluates two things:
How consistently the system produces correct answers across repeated runs
How long those responses take
Both of these dimensions matter – a system that is occasionally correct is not reliable, and a system that is consistently slow is not usable.
The System We Tested: Airline Policy
To validate the framework, we applied it to an airline policy agent network. In this network, agents interpret and explain airline policies, assisting customers with inquiries about baggage allowances, cancellations, and travel-related concerns. It answers customer questions about the airline's policies by pulling directly from locally stored policy documents, with each LLM-backed specialist agent owning a clearly scoped slice of the policy knowledge. Questions get routed to the right specialist, and answers get synthesized from multiple sources. This effectively creates a lightweight, document-grounded system similar to RAG, but without the overhead of vector databases, embeddings, or chunking pipelines. This is exactly the type of multi-agent system where correctness matters and errors have real consequences.
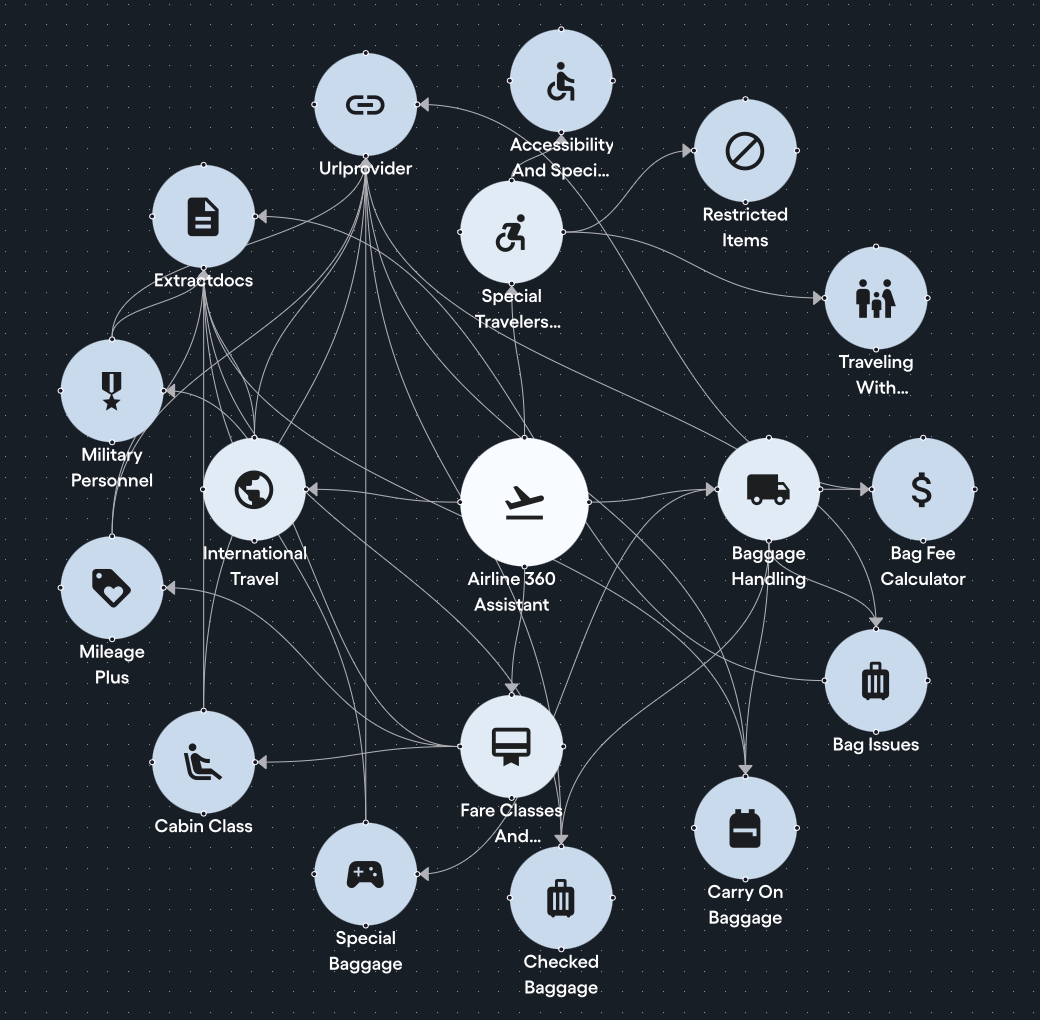
The tests quickly surfaced multiple failures we did not expect. Fixing them required iteration across several layers of the system, but the solutions that worked were consistent and generalized beyond this use case.
Here is what actually worked.
Bad Knowledge Documents and Vague Descriptions Break Routing
The first set of issues came from the knowledge layer and how agents were defined.
The source documents contained web-scraping artifacts such as navigation menus, footer links, and cookie banners. This noise made it harder for agents to retrieve and use the correct information.
Cleaning and restructuring the documents was a necessary first step. We stripped all of that out and reorganized the documents into logical categories, so each agent owns a clearly scoped slice of the knowledge base and queries can be routed to the right specialist with precision.
Routing failures were just as important.
In neuro-san, the frontman agent and any sub-agent assigned to route queries decide who to call based on the titles and descriptions of the agents available to them. When those descriptions are missing or buried inside sub-agent instructions, the routing agent has no visibility into what each specialist actually handles. It has no choice but to broadcast every query to all agents, which means wasted calls, wasted time, and wasted tokens.
Getting function descriptions right fixes this. A comprehensive, scope-accurate description that captures both what an agent handles and what it does not is what gives the routing agent the precision it needs.
Here is what the difference looks like:
// Before: vague description, frontman has no idea what this agent actually covers
{
name: "Baggage_Info"
function: ${aaosa_call}{
description: "Handles baggage related queries"
}
}
// After: specific description, frontman knows exactly when to invoke this agent
{
name: "Baggage_Info"
function: ${aaosa_call}{
description: """
Standard bag rules and fees: carry-on size/weight limits/fees,
personal item size rules, checked bag size/weight limits/fees,
overweight and oversized bag surcharges.
Does not cover bag problems after travel, nor non-standard
items like bikes, firearms, or sports gear.
"""
}
}With the vague "before" description, a question about bag problems after travel would have incorrectly routed to Baggage_Info, or with no description at all, the routing agent would have had to guess purely from the agent name, leading to frequent misroutes. With the specific "after" description, the routing agent knows exactly what Baggage_Info covers and, just as importantly, what it does not. The improvement in routing accuracy was immediately visible in our test results.
Five Prompt Patterns That Measurably Improved Accuracy
With the reliable test framework in place, every change we made to the agent network had a measurable outcome. That feedback loop is what led us to the techniques below.
1. Use Negative Instructions Over Positive Ones
Negative instructions outperformed positive ones every time. While research is mixed on this, our experience with neuro-san clearly favored telling the model what not to do.
// Before: positive instruction — agents often summarized or skipped edge cases
instructions: """
Keep all policy documents as-is in your response.
"""
// After: negative instruction — agents consistently return complete answers
instructions: """
NEVER paraphrase policy language; keep it as-is.
"""2. Use Formatting to Emphasize Critical Rules
Formatting cues matter more than expected. Bold markdown formatting and selective use of uppercase made a real difference in how consistently agents followed instructions. Since LLMs process and pass information in markdown format, cues that stand out naturally get more attention. That said, overusing them defeats the purpose. Reserve bold and uppercase for the critical instructions that truly cannot be missed.
// Before: plain text — critical rules blend into the prompt
instructions: """
Never filter or omit policy variations or omit restrictions,
exceptions, or safety rules.
"""
// After: bold + uppercase on critical constraints — agents follow them more reliably
instructions: """
**NEVER filter** or omit policy variations or omit restrictions,
exceptions, or safety rules — return **ALL** of them (by fare class,
membership status, route, or any other dimension).
"""3. Prevent Summarization of Critical Content
LLMs default to summarizing. That works for general use, but it creates problems for certain use cases. In the scenario for the airline policy network, anti-summarization rules were essential for policy content as general conversation creates serious issues for policy language. Important qualifications, exceptions, and conditional rules get dropped or reworded in ways that change their meaning. Explicitly instructing agents to preserve the original policy language made a measurable difference on tests that checked for specific conditional rules.
instructions: """
Always include all applicable policy language, conditions, and
qualifications in full — including all fee amounts, pricing tiers,
and every step of any multi-step procedure or item lifecycle.
"""4. Repeat Critical Instructions
Repeating critical instructions closed the last gap. The well-documented "lost in the middle" effect means instructions placed in the center of a long prompt are more likely to be ignored. Placing critical rules at both the beginning and end of agent instructions measurably improved consistency. The other techniques do the heavy lifting, but repeating key constraints is what takes the system from 90% to 95%, and in a production system, that margin matters.
// instructions_prefix holds the network's most critical rules as a shared variable
instructions_prefix: """
...critical rules defined once...
"""
// Each agent sandwiches its own logic between two copies of the prefix
instructions: ${instructions_prefix} """
You are the Carry On Baggage agent.
You handle carry-on and personal item rules, size limits,
and additional items.
...agent-specific instructions...
""" ${instructions_prefix}5. Specify Tool Calls Explicitly
Spelling out the exact tool name, parameter name, and expected value in an agent's instructions led to significantly more consistent tool use. Pairing this with an explicit rule to never use external knowledge closed the loop: agents must call the tool and must base their answer solely on what the tool returns. Without that specificity, agents could fall back on pre-trained knowledge instead of calling the tool, returning confident but wrong or outdated answers.
// Before: vague — agents sometimes skip the tool and answer from memory
instructions: """
Use the document tool to look up the relevant policy.
"""
// After: exact tool name, parameter, and value — agents call it every time
instructions: """
Always call ExtractDocs (app_name: "Carry On Baggage")
to get the full policy text. Answer only based on the
full policy text ONLY.
**NEVER use external knowledge** — base every answer strictly
on policy documents or sub-agent responses.
"""Lessons From Building the Test Framework
Use prompt optimization tools to iterate faster.
Prompt optimization tools significantly accelerated iteration. Feeding the current prompt, failing test cases, and expected outputs into an optimizer for the target model made it much easier to refine instructions.
Tools like OpenAI's prompt optimizer and Claude's prompt improver worked well in practice. The key difference was having the test framework in place. It provided objective metrics, so we could quickly determine whether a change actually improved performance or not.
Let the models show you where the problem is
Running each test multiple times revealed clear patterns in where failures originated.
When iterating on an agent network, we ran each test 10 times and used pass rates as a diagnostic:
Fewer than 3/10 passes usually indicated an issue with knowledge documents, tools, or acceptance criteria. The agent is not capable of producing the correct answer, which suggests something is missing or incorrect in the source material.
4–7/10 passes typically pointed to a routing problem. The agent can get the right answer, but it is not consistently reaching the correct specialist.
8+ passes meant the agent is capable, but the prompt is too loose. The remaining failures come from model variability rather than missing logic.
This simple three-tier breakdown made it much easier to focus on the right layer instead of guessing.
Start small and build on what works
We started with a single agent network and a small set of tests, then iterated based on failures.
It took time to identify which prompt patterns worked, how different models responded, and what was required to handle more complex queries reliably. Once those patterns became clear, they transferred well. Applying the same fixes to other agent networks resolved most issues with minimal changes.
Quantifying the Impact: Iteration Gains and Model Comparisons
We wanted to answer two questions: how much did our test-driven iterations actually improve the agent network, and how do different LLMs perform on the exact same network? Same instructions, same agents, same knowledge documents. Just swap the model.
We ran our 21-test airline policy suite across nine models: GPT-4o and GPT-5.2 from OpenAI, Claude Haiku 4.5, Sonnet 4.6, and Opus 4.6 from Anthropic, Gemini 3.1 Pro, Gemini 3 Pro, and Gemini 3 Flash from Google, and Qwen 3 (8b). Each test was run 10 times, and for a test case to pass, we required a perfect 10/10 score.
To show the impact of the iteration process, we evaluated the two OpenAI models twice: once on the original, untuned prompts and once after all test-driven improvements. GPT-5.2 went from passing just 5–9 tests to passing 20–21, purely through prompt changes guided by the test results.
With the agent network tuned, we then ran the full comparison across all nine models. The results were strong across the board. The leading models from each provider passed between 17 and 21 tests, with failures limited to just 1 or 2 runs out of 10. Claude Opus 4.6 achieved the best overall result, passing all 21 tests, with GPT-5.2 a close second. Figure 2 shows the full breakdown.
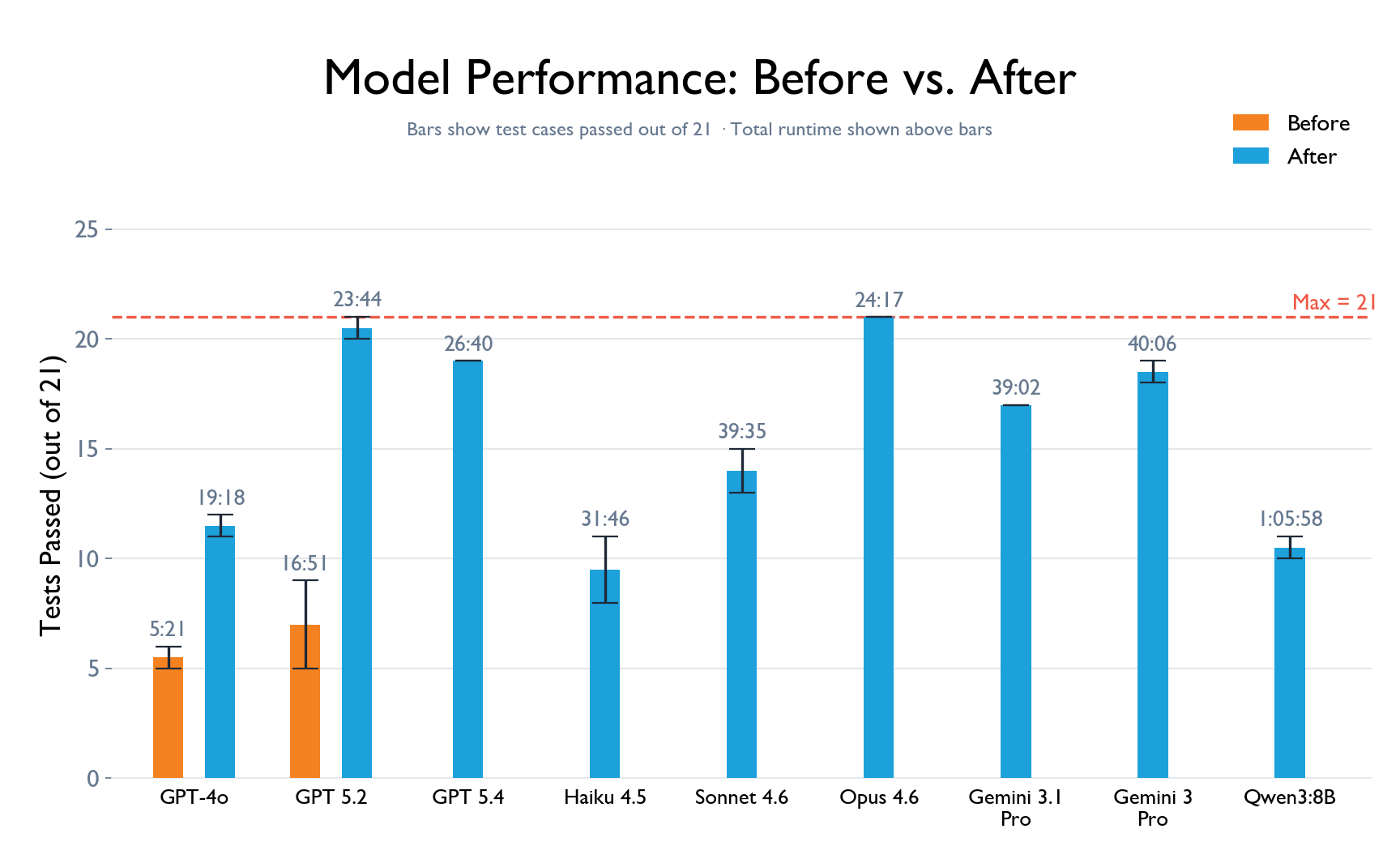
One advantage of this evaluation is matching the right model to the right use case, enabling decisions grounded in the actual shape of your queries rather than generic benchmark scores. For instance, straightforward questions scoped to a single agent's domain are handled well by GPT-5.2, which routes directly to the right specialist without unnecessary calls. In contrast, questions that span multiple agents and require synthesizing information across sources are where Claude Opus 4.6 shines, handling larger contexts more effectively and producing more complete answers. The choice also depends on practical constraints: token availability per provider, budget, and acceptable latency.
Together, these techniques — clean knowledge, precise descriptions, targeted prompts, and the right model — give you everything you need to build an agent network that performs reliably.
How to Build Reliable Agent Systems: Key Takeaways
Clean data matters more than you think—it directly impacts routing and output quality
Prompt structure significantly influences accuracy and consistency
Tool enforcement is critical to prevent hallucinations and ensure grounded responses
Testing frameworks are essential for maintaining reliability at scale
What's Next: Testing Built Into the Builder
Building a test framework manually takes effort, but the value is too significant to treat as optional. We are working on an agent system that automatically generates test frameworks for agent networks, integrated directly into neuro-san’s network builder. When you create a network, you will get a ready-to-run test framework alongside it.
No separate setup and no manual test writing to get started. Just a network and its test framework, ready to run from day one. This makes testing a built-in part of the development process, not an afterthought, and makes it easier to iterate toward reliable agent behavior from the start.

Data Scientist with 4+ years of experience building scalable intelligent systems, specializing in agentic AI and multimodal machine learning