June 1, 2026
How We Turned a 100-Page Annual Report into a Personalized Briefing with neuro-san

How We Turned a 100-Page Annual Report into a Personalized Briefing with neuro-san
A multi-agent system built on neuro-san that reads a LinkedIn profile, distributes retrieval across 25 document-scoped agents, and delivers a personalized, validated summary of any long-form document without asking the reader a single question.

Long-form content has an engagement problem. Enterprises produce enormous volumes of it: annual reports, technical documentation, regulatory filings, product briefs, internal knowledge bases. Most of it goes unread, not because it lacks value, but because the cost of finding the relevant parts is too high for any individual reader. A 100-page annual report might have five pages that matter to a given stakeholder. The other 95 are noise they have to wade through to get there.
The standard solution is search. You index the document, let people query it, and return the chunks that score highest against their query. That works for exploratory questions, but it puts the burden of knowing what to ask on the reader. It also doesn't use everything you know about who the reader is, their role, their domain, what they've been paying attention to, the organizational context they sit in.
We built a multi-agent system with neuro-san, our open-source multi-agent framework, that takes that profile signal and uses it to generate a personalized, validated summary of any long-form document. The system infers reader context from a LinkedIn profile, distributes retrieval across a network of document-scoped agents, assembles a tailored report, and validates every number in the output against the source before delivery. The test case was Cognizant's 2024 Annual Report, but the architecture works on any long-form content you want to make accessible at scale.
Why Retrieval Alone Doesn't Solve This
Before getting into the architecture, it's worth being precise about where standard RAG falls short for this use case.
Typical RAG pipelines chunk a document, embed those chunks, and retrieve the top-k by cosine similarity against a query. The retrieval quality is bounded by the quality of the query. If the user doesn't know what to ask, or asks at the wrong level of abstraction, the relevant content doesn't surface. There's also no reasoning layer to decide what's important for a specific person versus what's just topically adjacent.
Profile-driven retrieval changes the input. Instead of a query from the user, the system builds a contextual representation of the reader, job function, seniority, domain focus, organizational role, recent public activity, and uses that to drive what gets pulled from the document. The difference between "retrieve chunks about AI strategy" and "retrieve content relevant to a Chief AI Officer who oversees an AI research lab and has been publicly posting about AI platform adoption and enterprise AI risk" is significant. The second framing produces a much tighter, more actionable summary.
That's the core idea. The agent network is how you implement it reliably at scale.
Agent Network Architecture
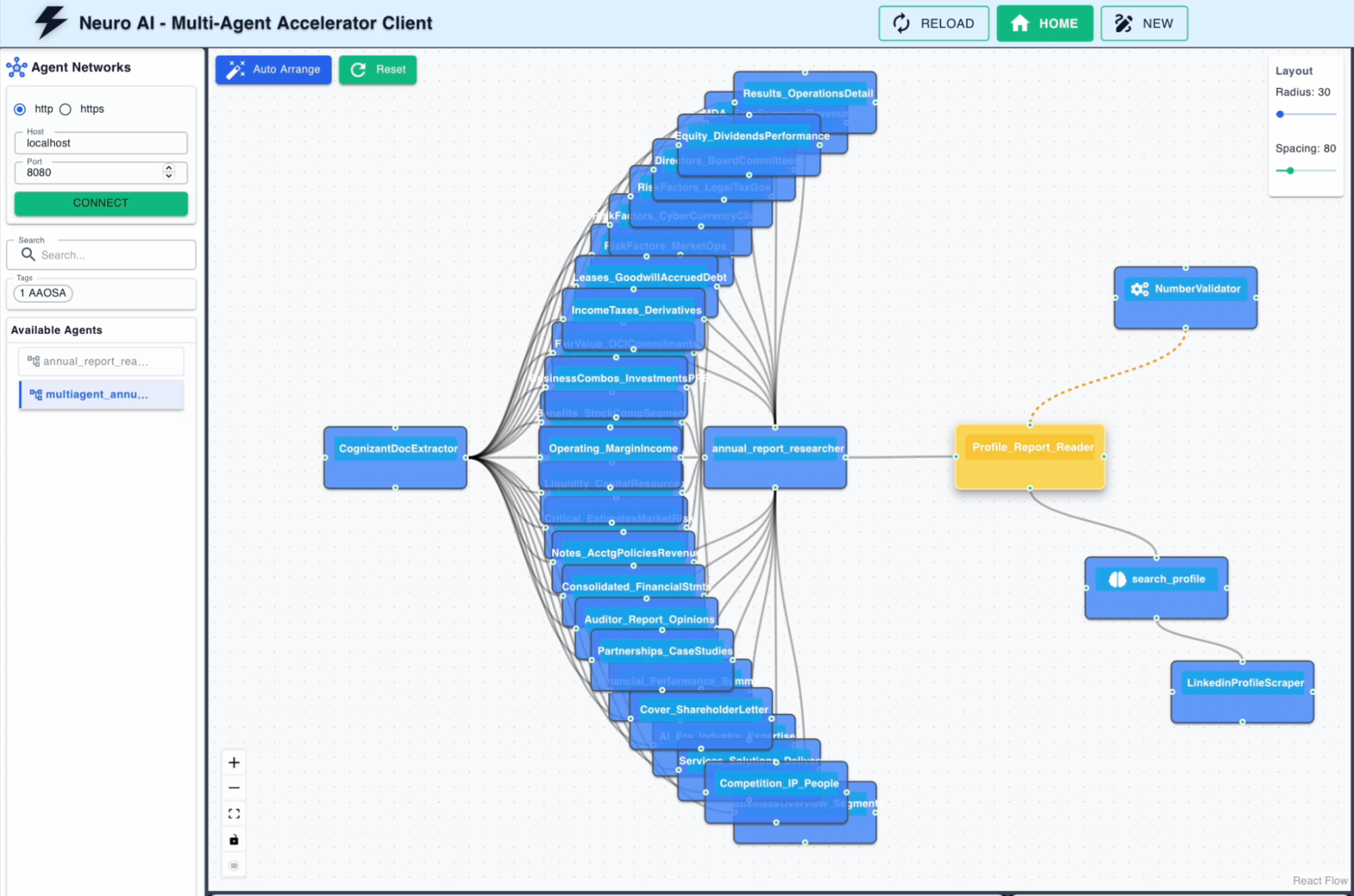
The network is built on neuro-san and follows the AAOSA coordination model, where agents evaluate incoming context and claim responsibility for the parts they're equipped to handle, rather than waiting to be assigned work by a central orchestrator. Here's how the components fit together.
Profile Report Reader (Frontman Agent)
The frontman is the entry point and coordinator for the network. It receives the user's input, which in this case is a LinkedIn profile URL and the document to be summarized, and manages the flow between downstream agents. In neuro-san's AAOSA architecture, the frontman doesn't route work manually. It passes context into the network, and agents self-select based on what they're configured to handle. The Profile Report Reader holds state across the full pipeline and is responsible for delivering the final output.
Search Profile Element Agent + LinkedIn Scraper Tool
Once the frontman has the profile URL, it delegates to the Search Profile Element agent, which calls a LinkedIn profile scraper tool. The scraper returns structured profile data: current title, employer, career history, recent posts, and the topics the person has been publicly engaging with. This gets normalized into a profile context object that downstream agents use as their retrieval signal. The richness of this signal matters. Job title alone is a weak signal. Job title combined with recent post topics, organizational scope, and domain focus gives the document agents enough context to make meaningful filtering decisions.
Annual Report Researcher + 25 Document-Scoped Sub-Agents
This is where the bulk of the retrieval and reasoning happens. The Annual Report Researcher coordinates a network of approximately 25 specialized sub-agents, each one scoped to a specific section of the source document: financial performance, AI strategy, business segment breakdowns, workforce programs, client case studies, risk factors, and so on. Each sub-agent receives the reader profile context and independently determines whether its section contains content relevant to that reader. The agents that find relevant content return summarized extracts. The ones that don't, return nothing. The Researcher then assembles the responses into a coherent, structured summary.
This design has a few advantages over a single retrieval pass. First, the retrieval is parallelized across the document rather than run sequentially. Second, each sub-agent can apply section-specific reasoning about what counts as relevant for a given profile, rather than applying a generic similarity score. Third, adding coverage for a new document type or expanding to a new source is a matter of adding or reconfiguring sub-agents, not rewriting the pipeline.
Number Validator Tool
Before the final output reaches the user, a Number Validator tool runs over every numerical claim in the assembled summary and cross-checks it against the source document. Any figure that can't be verified gets flagged, and the pipeline routes back to the Annual Report Researcher for a correction pass. This step runs before delivery, so the user only ever sees a validated output.
This is not a minor detail. Personalized summaries generated by LLMs carry real hallucination risk, and hallucinated numbers in a financial document have consequences. The validation loop is what makes the output trustworthy enough to act on rather than just interesting to look at.
Two Profiles, One Document, Completely Different Outputs
To validate that the network was actually personalizing rather than just summarizing, we ran two profiles with very different professional contexts through the same document.
Profile 1: Babak Hodjat, Chief AI Officer, Cognizant
Babak is the Chief AI Officer at Cognizant AI Lab, with a background as a CTO and long history in AI research and enterprise AI deployment. The network's output for his profile was structured around his interests, including Cognizant's AI strategy and leadership positioning, the AI platforms the company has built and is scaling, revenue performance tied to AI-driven engagements, the AI Labs research program, and AI-related risk factors at the enterprise level.
The report reflected the scope and depth you'd expect a C-suite technology executive to care about: strategic direction, organizational performance, platform bets, and risk. Heavy on numbers and forward-looking signals.
Profile 2: Healthcare Analyst, Cognizant
The second profile was a healthcare-focused financial analyst. The report output looked almost nothing like Babak's. The network surfaced insights such as health sciences segment definition and revenue performance, healthcare industry risk factors specific to Cognizant's exposure, AI applications in Cognizant's healthcare and life sciences case studies, and competitive landscape and go-to-market structure.
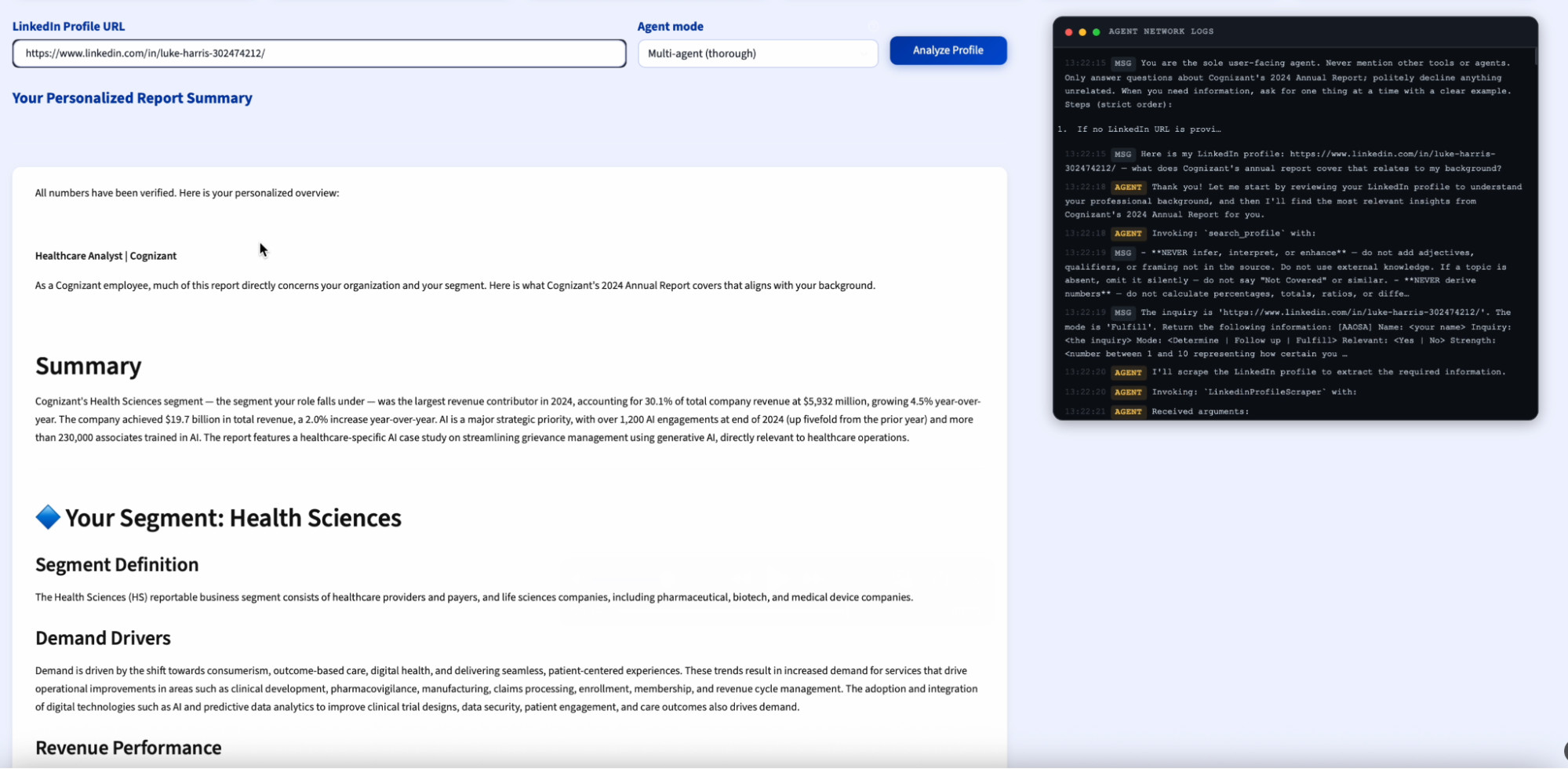
The framing shifted from enterprise AI strategy to industry-specific performance and organizational context relevant to an analyst. The content pulled was drawn from completely different sections of the same document.
The contrast between the two outputs is the clearest demonstration of what the system is actually doing. It's not summarizing the document and personalizing the framing, but rather selecting different content entirely based on who the reader is.
Generalizing Beyond Annual Reports
The annual report was a useful test case because it's a high-stakes, high-density document with a genuinely diverse audience. But nothing in this architecture is specific to annual reports or to Cognizant.
The same network structure applies to any long-form content where different readers have legitimately different information needs. Technical documentation with audience segments ranging from developers to architects to product managers. Regulatory filings where legal, compliance, and finance teams each care about different sections. Internal knowledge bases where relevance is a function of role and team. RFP responses where the client's procurement team and technical evaluators need different cuts of the same material.
The key design decision is how you model the reader. LinkedIn profile data works well for professional context because it's structured, public, and rich enough to infer role, domain, seniority, and interests. But the profile signal can come from anywhere: internal HR systems, CRM data, user-provided context, or session behavior. The retrieval network doesn't care where the profile came from as long as it has enough signal to differentiate what's relevant.
The document coverage layer, the 25 sub-agents in this implementation, scales with the size and structure of the source content. For a 100-page document, 25 agents with section-scoped context worked well. A larger corpus or a more complex document structure would need a different partitioning strategy, but the coordination model stays the same.
Get Started
If you want to explore the framework behind this demo, neuro-san is open source and available on GitHub. If you want to run this specific use case yourself, you can download it directly here.

Data Scientist with 4+ years of experience building scalable intelligent systems, specializing in agentic AI and multimodal machine learning