June 2, 2026
LLM Fine-Tuning Doesn't Have to Mean Forgetting: How We Fixed a Key Problem in Evolution Strategies

LLM Fine-Tuning Doesn't Have to Mean Forgetting: How We Fixed a Key Problem in Evolution Strategies
New research demonstrates how Evolution Strategies can continuously fine-tune LLMs while preserving existing capabilities and reducing performance drift.
When you fine-tune a large language model on a new task, there's a well-documented risk lurking in the background: the model gets better at what you're training it on, but quietly starts getting worse at things it already knew how to do. Researchers call this catastrophic forgetting, or prior-task forgetting, and it has been one of the stubborn challenges in machine learning since the late 1980s.
The stakes today are considerably higher than they were then. LLMs are increasingly being deployed in production environments where they need to continuously adapt, learning new tasks, adjusting to new domains, and integrating new information over time. In those settings, a model that forgets its prior capabilities every time it learns something new is not a usable system. Solving the forgetting problem is not an academic exercise; it's a prerequisite for building AI that can keep improving after deployment without requiring a full retraining cycle every time something changes.
In our earlier research on LLM post-training using Evolution Strategies (ES), we showed that ES is a compelling, simpler alternative to reinforcement learning. Unlike RL, which requires backpropagation and significant infrastructure to manage gradients and memory, ES optimizes model parameters through stochastic perturbations in weight space using only forward passes, making it naturally parallelizable, infrastructure-light, and compatible with inference-optimized hardware. That work was well-received, but a concern followed it closely. Several subsequent papers reported that ES induces more prior-task forgetting than RL methods, raising a legitimate question about whether ES is actually suitable for real deployment settings where preserving prior capabilities matters.
In our latest research, Overcoming Forgetting in LLM Fine-Tuning with Evolution Strategies, we take a closer look at what this forgetting actually is and trace it back to its root cause in the ES optimization dynamics. Building on that understanding, we introduce Anchored Weight Decay (AWD), a minimal modification to the ES update rule that constrains the drift responsible for forgetting. The result is that continual fine-tuning with ES, without the compute overhead of RL and without the risk of degrading prior skills, is now a realistic option for production systems.
Prior-Task Forgetting in LLMs: Temporary Drift, Not Permanent Damage
The first thing that shifts when you look at the full training trajectory, rather than just measuring accuracy at the endpoint, is the story changes. In some cases, ES can degrade performance on previously learned tasks by comparing base model accuracy to final accuracy after training. What our analysis shows is that if you track prior-task accuracy throughout training, you often see something more nuanced: accuracy drops in the early iterations, then recovers, sometimes fully, by the time training completes. For example, on HellaSwag, a commonsense reasoning benchmark, we observed accuracy fall by 8 percentage points before bouncing back to near-baseline performance by the final iteration.
This distinction matters more than it might first appear. Catastrophic forgetting implies something permanent, a loss that requires retraining from scratch to undo. What we're actually observing in most cases looks far more like a transient drift through a suboptimal region of weight space during training. The model wanders, then finds its way back. That reframing changes how you think about whether ES is viable for production systems, and what intervention is actually needed to make it robust.
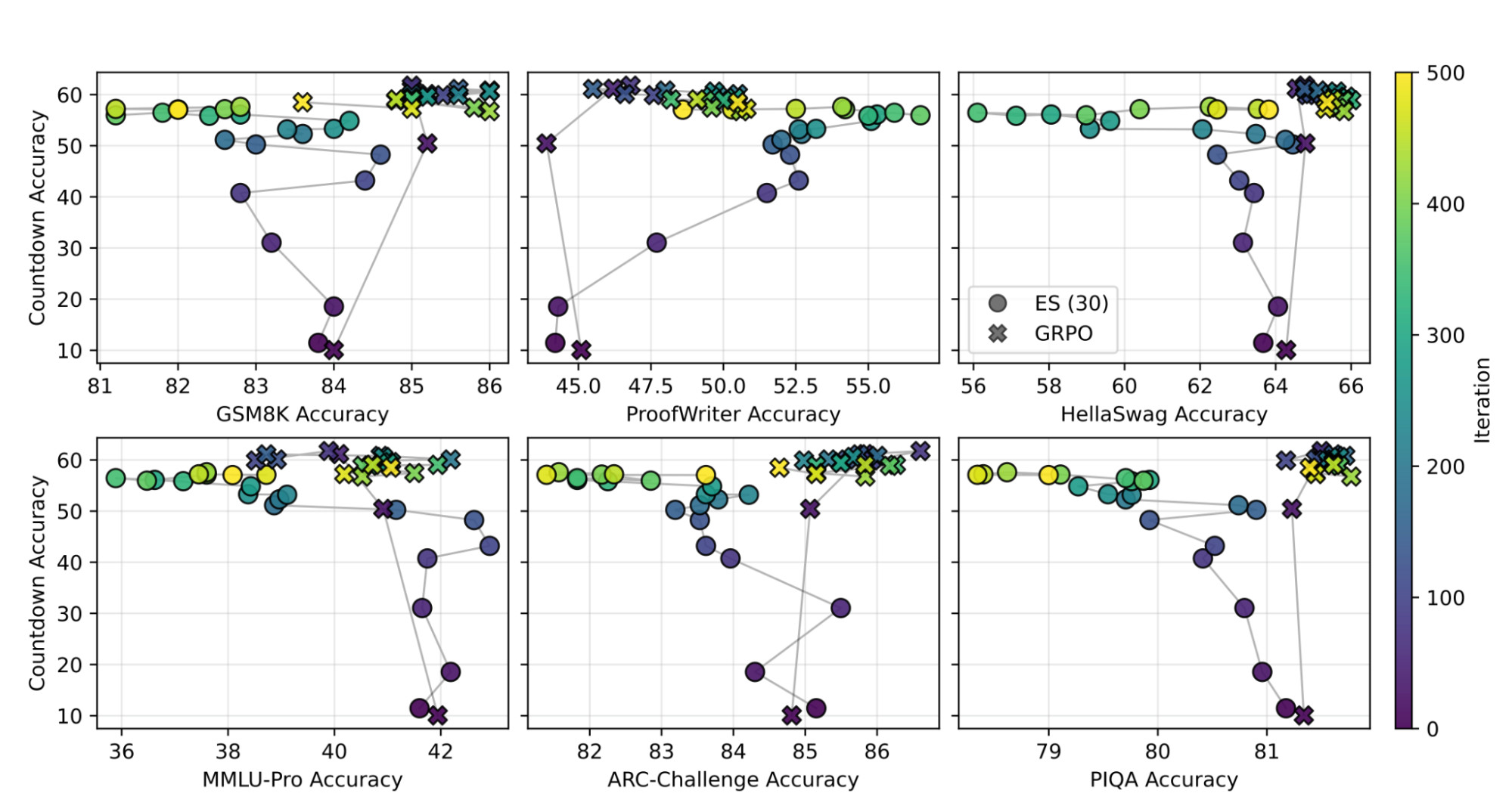
Figure 1. Individual prior-task accuracies when training on Countdown as the target task. A performance drift rather than irreversible forgetting is observed across multiple tasks. Performance on HellaSwag, a commonsense reasoning benchmark, drops by 8% accuracy over the first 300 iterations, but subsequently recovers to its original level by the final iteration.
The second finding complicates the narrative further. When we apply the same forgetting analysis to GRPO, one of the most widely-used RL methods for LLM fine-tuning, we observe significant prior-task forgetting in multiple settings too. In some configurations, GRPO produces accuracy drops on prior tasks that are comparable to or worse than ES, including a substantial degradation on mathematical reasoning tasks when training on logical reasoning. Prior-task forgetting during LLM fine-tuning is not a specific failure mode of Evolution Strategies. It appears to be a general characteristic of how post-training interacts with model weights, and framing it otherwise misidentifies where the real problem lives.
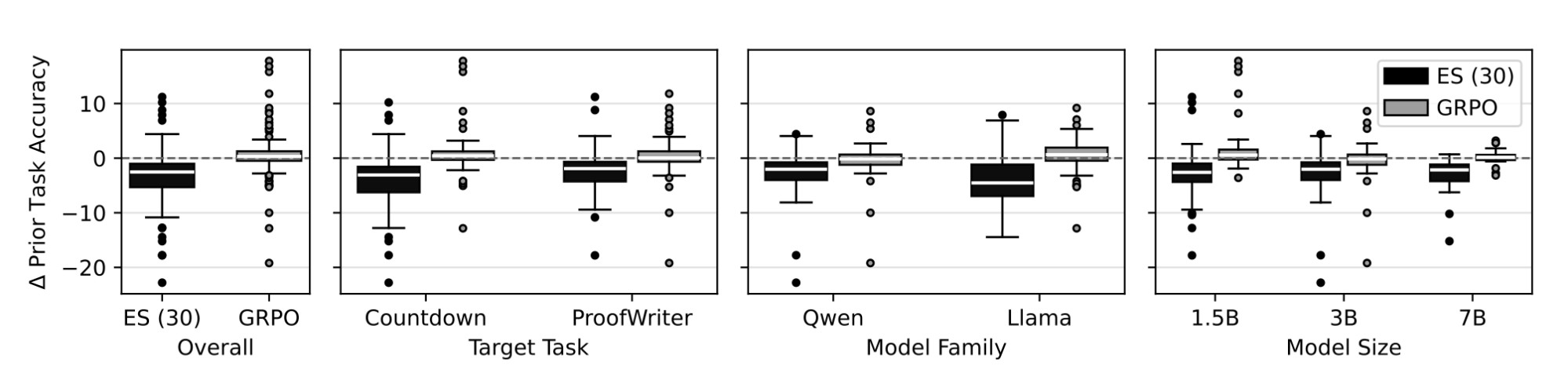
Figure 2. Target task accuracy vs. average prior-task accuracy throughout training. Colors denote the iteration within the training process. For ES, prior-task accuracy exhibits noticeable drift, where accuracy decreases initially but often recovers later in training. GRPO exhibits less drift on average, but can also lead to severe forgetting in some settings.
Why ES Shows More Forgetting on Average: The Random Walk Problem
Understanding why ES produces more forgetting than GRPO on average, even if both can exhibit it, requires looking at how the two methods move through weight space during training. RL methods like GRPO optimize in token space and tend to stay relatively stationary in weight space when the reward signal diminishes. ES is fundamentally different in this regard. It samples random perturbations across a population of model variants, and when those perturbations don't strongly constrain the target task, the optimizer is free to wander in directions that have nothing to do with what it's being trained on.
Prior theoretical work on ES optimization dynamics describes this as a random walk in the low-curvature directions of weight space, the directions weakly constrained by the target task objective. Over many training iterations, that walk accumulates. Cumulative weight deviation grows linearly with the number of training steps and shrinks inversely with population size, which explains something we see clearly in our data: larger ES populations substantially reduce forgetting. At population size 30, average prior-task accuracy drops by around 5 percentage points. At population size 256, that drop nearly disappears. The random walk is diluted because individual perturbations carry less relative weight in the aggregate update.
The problem with simply scaling population size is obvious. Running 256 parallel model evaluations per training step instead of 30 multiplies computational cost directly, and for most teams doing continual fine-tuning at scale, that's not a realistic path forward.
Figure 3. Change in final prior-task accuracy under different target tasks and base models. Boxplots show the change in prior-task accuracy for ES and GRPO across target tasks, model families (Qwen, Llama), and model sizes (1.5B, 3B, 7B). No significant dependence on model family or size is observed, suggesting the effect is driven by training dynamics rather than model-specific properties.
Anchored Weight Decay: A Small Change with a Large Effect
Anchored Weight Decay, which we call AWD, starts from the insight that if random walk in unconstrained directions is driving forgetting, the right intervention is to constrain that walk directly rather than try to limit it with a larger population. The mechanism is simple: after each parameter update, the model weights are gently pulled back toward the original pre-training weights, with the strength of that pull controlled by a penalty factor. The further the current weights have drifted from where training started, the stronger the corrective force pulling them back.
On the implementation side, AWD adds a weight decay step directly into the ES update rule. Because ES doesn't use backpropagation, you can't add a regularization term to a loss function in the usual way, so the decay happens at the weight level instead. The original model weights need to be accessible during training, which we handle by storing them in pinned RAM and streaming them layer by layer to the GPU during the update. In practice, this adds roughly 1 to 2 percent to total runtime, which is negligible.
The results are consistent across everything we tested. AWD reduces the average prior-task accuracy drop from around 5 percentage points to near zero at population size 30, matching the level of forgetting mitigation you'd otherwise need much higher population sizes to achieve. Target-task performance is preserved throughout, and the penalty factor gives practitioners a clean knob to tune based on how much prior-task retention matters for their specific use case.
One finding from the weight-update analysis is particularly worth highlighting. Even with AWD applied, the euclidean norm of weight changes under ES stays considerably larger than what GRPO produces. But what AWD changes is not the magnitude of the updates; it's their character. The distributional shift on prior tasks, measured by KL-divergence between the base model and the fine-tuned model, becomes comparable to GRPO once AWD is in place. That tells you the norm of weight updates alone isn't what causes prior-task forgetting. It's the unconstrained drift in directions irrelevant to the target task, and AWD addresses that directly.
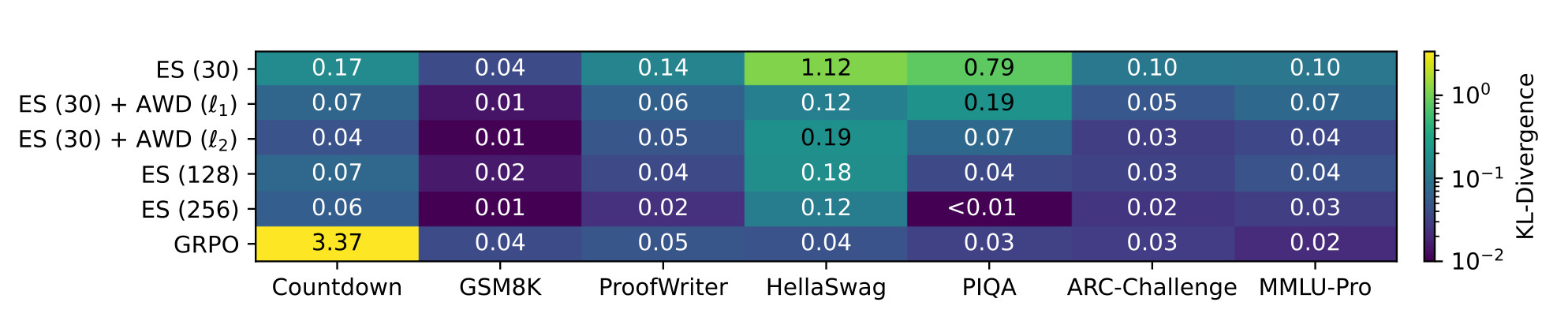
Figure 4. KL-divergence between the base model and the final model trained on Countdown. ES with a small population size causes larger distributional shift on prior tasks than GRPO. Increasing population size or adding AWD mostly closes this gap. On the target task, GRPO shows very high divergence while it remains low for all ES variants, despite all achieving similar target-task accuracy.
What This Unlocks for Continual Learning
The most direct implication of this work is for systems where models need to keep adapting without losing what they already know. Enterprise AI deployments, agentic workflows, and multi-task fine-tuning pipelines all depend on that property. Until now, the risk of forgetting was a real reason to hesitate before using ES in those contexts. AWD largely removes that hesitation.
ES with AWD is a viable and computationally efficient option for continual LLM fine-tuning. Because ES relies only on forward passes, the entire fine-tuning process can run on inference hardware without a separate training stack, which means teams can continuously adapt deployed models without the memory management, gradient synchronization, and infrastructure overhead that RL pipelines require. That's a meaningful operational advantage, and AWD is what makes it safe to use in settings where prior-task preservation is non-negotiable.
It's also worth acknowledging what AWD changes about ES more broadly. The random walk that AWD constrains is part of what allows ES to explore more freely than RL, and that exploration has potential value in settings where broad search matters more than tight prior-task retention, scientific discovery tasks, for instance, or optimization problems where escaping local optima is the priority. AWD makes this tradeoff explicit and tunable. Teams who need strong prior-task preservation can dial the penalty factor up; teams who want more aggressive exploration can dial it down.
What Comes Next
This paper is part of a longer research program building on our earlier work establishing ES as a competitive, gradient-free approach to LLM post-training. The prior-task forgetting problem in verifiable reasoning domains is now largely addressed. What we want to understand next is how post-training dynamics interact with alignment and safety properties. As models are deployed in agentic settings that require continuous adaptation, understanding whether fine-tuning methods preserve or erode safety-relevant behaviors becomes increasingly critical, and that's where the next phase of this research is headed.
The paper and all experimental code are available at https://github.com/kschweig/es-awd.

Research Scientist at Cognizant AI Lab that specializes in ML, Deep Learning, AI Robustness, and uncertainty estimation